9.0. Netwerkproblemen oplossen
9.0.1. Inleiding
Als een netwerk of een deel van een netwerk uitvalt, kan dit ernstige negatieve gevolgen hebben voor het bedrijf. Netwerkbeheerders moeten een systematische aanpak gebruiken voor het oplossen van problemen wanneer netwerkproblemen optreden om het netwerk zo snel mogelijk weer volledig in productie te brengen.
Het vermogen van een netwerkbeheerder om netwerkproblemen snel en efficiënt op te lossen, is een van de meest gewilde vaardigheden in IT. Bedrijven hebben mensen nodig met sterke netwerkproblemen en de enige manier om deze vaardigheden te verwerven is door praktische ervaring en door systematische benaderingen voor probleemoplossing te gebruiken.
Dit hoofdstuk beschrijft de netwerkdocumentatie die moet worden onderhouden en algemene procedures, methoden en hulpmiddelen voor het oplossen van problemen. Typische symptomen en oorzaken op verschillende lagen van het OSI-model worden ook besproken. Dit hoofdstuk bevat ook informatie over het oplossen van problemen met paden en ACL’s.
9.1. Methodiek voor probleemoplossing
9.1.1. Netwerkdocumentatie
9.1.1.1. Het netwerk documenteren
Om netwerkbeheerders in staat te stellen een netwerk te bewaken en problemen op te lossen, moeten ze beschikken over een volledige set nauwkeurige en actuele netwerkdocumentatie. Deze documentatie omvat:
- Configuratiebestanden, inclusief netwerkconfiguratiebestanden en configuratiebestanden van het eindsysteem
- Fysieke en logische topologiediagrammen
- Een basisprestatieniveau
Netwerkdocumentatie stelt netwerkbeheerders in staat om netwerkproblemen efficiënt te diagnosticeren en te corrigeren, op basis van het netwerkontwerp en de verwachte prestaties van het netwerk onder normale bedrijfsomstandigheden. Alle netwerkdocumentatie-informatie moet op één locatie worden bewaard, hetzij als hardcopy, hetzij op het netwerk op een beveiligde server. Back-updocumentatie moet op een aparte locatie worden bewaard en bewaard.
| Apparaatnaam, Model | Interface naam | MAC Adres | IPv4 adres | IPv6 adressen | IP routeringsprotocol |
|---|---|---|---|---|---|
| R1, Cisco 1941, c1900-universalk9-mz.SPA.152-4.M1 | G0/0 | 0007.8580.a159 | 192.168.10.1/24 | 2001:db8:cafe:10::1/64 fe80::1 | EIGRPv4 10 EIGRPv6 20 |
| G0/1 | 0007.8580.a160 | 192.168.11.1/24 | 2001:db8:cafe:11::1/64 fe80::1 | EIGRPv4 10 EIGRPv6 20 | |
| S0/0/0 | 10.1.1.1/30 | 2001:db8:acad:20::1/64 fe80:: | EIGRPv4 10 EIGRPv6 20 | ||
| S0/0/1 | |||||
| R2, Cisco 1941, c1900-universalk9-mz.SPA.152-4.M1 | S0/0/0 | 10.1.1.2/30 | 2001:db8:acad:20::2/64 fe80::2 | EIGRPv4 10 EIGRPv6 20 |
Netwerkconfiguratiebestanden
Netwerkconfiguratiebestanden bevatten nauwkeurige, actuele gegevens over de hardware en software die in een netwerk worden gebruikt. Binnen de netwerkconfiguratiebestanden zou een tabel moeten bestaan voor elk netwerkapparaat dat op het netwerk wordt gebruikt, met alle relevante informatie over dat apparaat. Afbeelding 1 toont voorbeelden van netwerkconfiguratietabellen voor twee routers. De volgende tabel is een vergelijkbare tabel voor een LAN-switch.
| Switchnaam, Model, Management IP Adressen | Poort | Snelheid | Duplex | STP | Port Fast | Trunk Status | EtherChannel L2 of L3 | VLAN’s | Key |
|---|---|---|---|---|---|---|---|---|---|
| S1, Cisco WS-2960-24TT, 192.168.10.2/24, 2001:db6:acad:99::2, c2960-lanbasek9-mz.150-2.SE | F0/1 | 100 | Auto | Fwd | No | On | None | 1 | Connect to R1 |
| F0/2 | 100 | Auto | Fwd | Yes | No | None | 1 | Connects to PC1 | |
| F0/3 | Not connected |
Informatie die in een apparaattabel kan worden vastgelegd, omvat:
- Type apparaat, modelaanduiding
- IOS-afbeeldingsnaam
- Hostnaam apparaatnetwerk
- Locatie van het apparaat (gebouw, verdieping, kamer, rack, paneel)
- Als het een modulair apparaat is, vermeld dan alle moduletypen en in welke modulesleuf ze zich bevinden
- Adressen van datalinklaag
- Adressen van netwerklagen
- Alle aanvullende belangrijke informatie over fysieke aspecten van het apparaat
Configuratiebestanden van het eindsysteem
Configuratiebestanden van het eindsysteem zijn gericht op de hardware en software die wordt gebruikt in eindsysteemapparaten, zoals servers, netwerkbeheerconsoles en gebruikerswerkstations. Een onjuist geconfigureerd eindsysteem kan een negatieve invloed hebben op de algehele prestaties van een netwerk. Om deze reden kan het erg handig zijn om bij het oplossen van problemen een voorbeeld van een baselinerecord te hebben van de hardware en software die op apparaten wordt gebruikt en vastgelegd in de documentatie van het eindsysteem, zoals weergegeven in de volgende tabel.
| Apparaatnaam, Doel | Besturingssysteem | MAC-adres | IP-adres | Standaard Gateway | DNS Server | Netwerkapplicaties |
|---|---|---|---|---|---|---|
| PC2 | Windows 8 | 5475.D08E.9AD8 | 192.168.11.10/24 | 192.168.11.1/24 | 192.168.11.11/24 | HTTP, FTP |
| 2001:DB8:ACAD:11:5075: D0FF:FE8E:9AD8/64 | 2001:DB8:ACAD:11::1 | 2001:DB8:ACAD:11::99 | ||||
| SRV1 | Linux | 5475.D08E.9AD8 | 192.168.20.254/24 | 192.168.20.1/24 | 192.168.20.1/24 | FTP, HTTP |
| 2001:DB8:ACAD:4::100/64 | 2001:DB8:ACAD:4::1 | 2001:DB8:ACAD:1::99 |
Voor het oplossen van problemen kan de volgende informatie worden gedocumenteerd in de configuratietabel van het eindsysteem:
- Apparaatnaam (doel)
- Besturingssysteem en versie
- IPv4- en IPv6-adressen
- Subnetmasker en prefixlengte
- Standaard gateway-, DNS-server- en WINS-serveradressen
- Alle netwerktoepassingen met hoge bandbreedte die door het eindsysteem worden uitgevoerd
9.1.1.2. Netwerktopologiediagrammen
Netwerktopologiediagrammen houden de locatie, functie en status van apparaten op het netwerk bij. Er zijn twee soorten netwerktopologiediagrammen: de fysieke topologie en de logische topologie.
Fysieke topologie
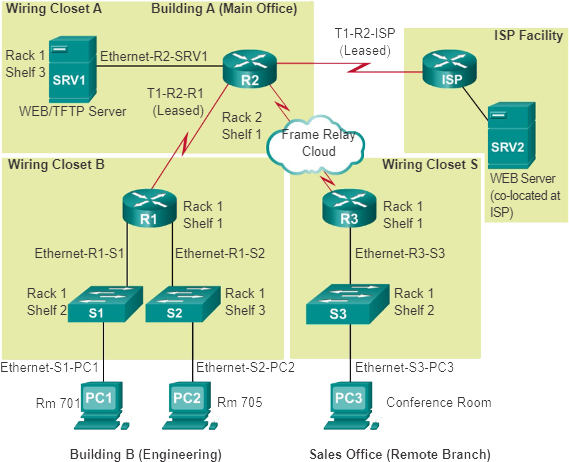
Een fysieke netwerktopologie toont de fysieke lay-out van de apparaten die op het netwerk zijn aangesloten. Het is noodzakelijk om te weten hoe apparaten fysiek zijn verbonden om problemen met de fysieke laag op te lossen. De informatie die in het diagram wordt vastgelegd, omvat doorgaans:
- Soort apparaat
- Model en fabrikant
- Besturingssysteemversie
- Kabeltype en identificatie
- Kabelspecificatie:
- Type connector
- Eindpunten bekabeling
De onderstaande afbeelding toont een voorbeeld van een fysiek netwerktopologiediagram.
Logische topologie
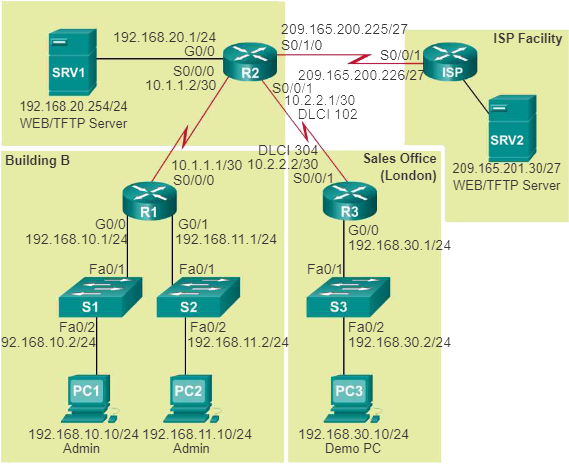
Een logische netwerktopologie illustreert hoe apparaten logisch zijn verbonden met het netwerk, wat betekent hoe apparaten daadwerkelijk gegevens over het netwerk overbrengen wanneer ze communiceren met andere apparaten. Symbolen worden gebruikt om netwerkelementen weer te geven, zoals routers, servers, hosts, VPN-concentrators en beveiligingsapparaten. Bovendien kunnen verbindingen tussen meerdere locaties worden weergegeven, maar vertegenwoordigen deze geen werkelijke fysieke locaties. Informatie die is vastgelegd in een logisch netwerkdiagram kan zijn:
- Apparaat-ID’s
- IP-adres en prefixlengtes
- Interface-ID’s
- Connectie type
- DLCI voor virtuele circuits
- Site-naar-site VPN’s
- Routeringsprotocollen
- Statische routes
- Datalink-protocollen
- Gebruikte WAN-technologieën
De volgende afbeelding toont een voorbeeld van een logische IPv4-netwerktopologie. Hoewel IPv6-adressen ook in dezelfde topologie kunnen worden weergegeven, kan het duidelijker zijn om een apart logisch IPv6-netwerktopologiediagram te maken.
9.1.1.3. Een netwerkbasislijn tot stand brengen
Basisprestatieniveau
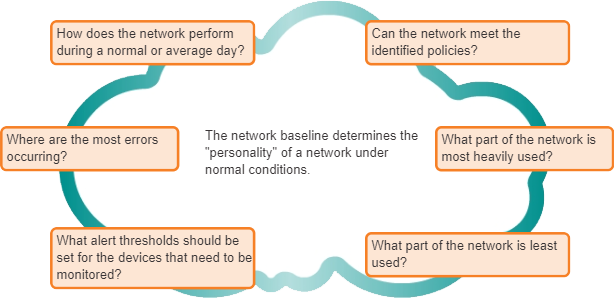
Het doel van netwerkmonitoring is om de netwerkprestaties te bekijken in vergelijking met een vooraf bepaalde baseline. Een baseline wordt gebruikt om normale netwerk- of systeemprestaties vast te stellen. Het vaststellen van een baseline voor netwerkprestaties vereist het verzamelen van prestatiegegevens van de poorten en apparaten die essentieel zijn voor de werking van het netwerk. De afbeelding toont verschillende vragen die worden beantwoord met een baseline.
Door de initiële prestaties en beschikbaarheid van kritieke netwerkapparaten en -koppelingen te meten, kan een netwerkbeheerder het verschil bepalen tussen abnormaal gedrag en de juiste netwerkprestaties naarmate het netwerk groeit of verkeerspatronen veranderen. De baseline geeft ook inzicht in de vraag of het huidige netwerkontwerp kan voldoen aan de bedrijfseisen. Zonder baseline bestaat er geen standaard om de optimale aard van netwerkverkeer en congestieniveaus te meten.
Analyse na een eerste baseline heeft ook de neiging om verborgen problemen aan het licht te brengen. De verzamelde gegevens tonen de ware aard van congestie of potentiële congestie in een netwerk. Het kan ook gebieden in het netwerk aan het licht brengen die onderbenut zijn en vaak leiden tot herontwerp van het netwerk, op basis van kwaliteits- en capaciteitswaarnemingen.
Omdat de initiële basislijn voor netwerkprestaties de basis vormt voor het meten van de effecten van netwerkwijzigingen en de daaropvolgende pogingen om problemen op te lossen, is het belangrijk om dit zorgvuldig te plannen.
Voer de volgende stappen uit om de eerste baseline te plannen:
Stap 1. Bepaal welke soorten gegevens u wilt verzamelen.
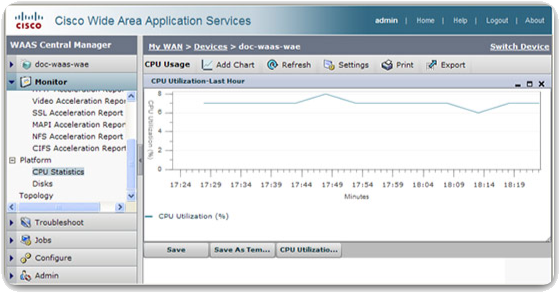
Begin bij het uitvoeren van de initiële baseline met het selecteren van een paar variabelen die het gedefinieerde beleid vertegenwoordigen. Als er te veel gegevenspunten worden geselecteerd, kan de hoeveelheid gegevens overweldigend zijn, waardoor analyse van de verzamelde gegevens moeilijk wordt. Begin eenvoudig en pas het gaandeweg aan. Enkele goede startmaatregelen zijn interfacegebruik en CPU-gebruik. De onderstaande afbeelding toont schermafbeeldingen van CPU-gebruiksgegevens, zoals weergegeven door de Cisco Wide Area Application Services (WAAS)-software.
Stap 2. Identificeer apparaten en poorten van belang.
Gebruik de netwerktopologie om die apparaten en poorten te identificeren waarvoor prestatiegegevens moeten worden gemeten. Apparaten en poorten van belang zijn onder meer:
- Netwerkapparaatpoorten die verbinding maken met andere netwerkapparaten
- Servers
- Sleutelgebruikers
- Al het andere dat van cruciaal belang wordt geacht voor de bedrijfsvoering
Een logisch netwerktopologiediagram kan handig zijn bij het identificeren van belangrijke apparaten en poorten die moeten worden bewaakt. In de volgende afbeelding heeft de netwerkbeheerder bijvoorbeeld de apparaten en poorten gemarkeerd die van belang zijn om te controleren tijdens de basislijntest. De apparaten die van belang zijn, zijn onder meer PC1 (de Admin-terminal) en SRV1 (de web-/TFTP-server). De poorten van belang zijn onder meer de poorten op R1, R2 en R3 die verbinding maken met de andere routers of met switches, en op R2, de poort die verbinding maakt met SRV1 (G0/0).
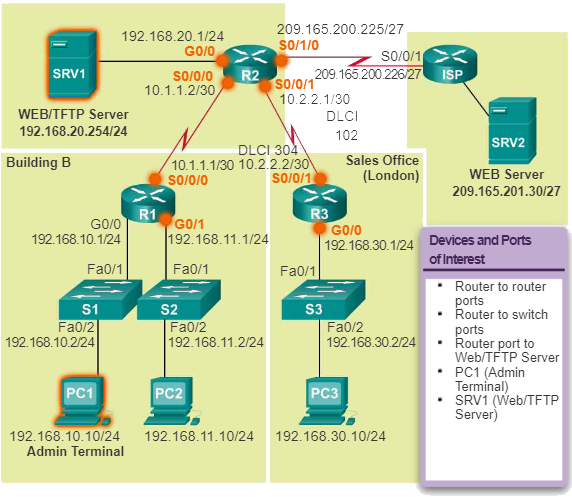
Door de lijst met poorten die worden opgevraagd in te korten, zijn de resultaten beknopt en wordt de belasting van het netwerkbeheer geminimaliseerd. Onthoud dat een interface op een router of switch een virtuele interface kan zijn, zoals een switch virtual interface (SVI).
Stap 3. Bepaal de baseline duur.
De tijdsduur en de basisinformatie die wordt verzameld, moeten voldoende zijn om een typisch beeld van het netwerk te krijgen. Het is belangrijk dat de dagelijkse trends van het netwerkverkeer worden gemonitord. Het is ook belangrijk om te monitoren op trends die zich over een langere periode voordoen, zoals wekelijks of maandelijks. Om deze reden moet de gespecificeerde periode bij het vastleggen van gegevens voor analyse ten minste zeven dagen lang zijn.
De onderstaande afbeelding toont voorbeelden van verschillende schermafbeeldingen van trends in CPU-gebruik die zijn vastgelegd over een dagelijkse, wekelijkse, maandelijkse en jaarlijkse periode. Merk in dit voorbeeld op dat de werkweektrends te kort zijn om de terugkerende piek in het gebruik elk weekend op zaterdagavond te laten zien, wanneer een databaseback-upbewerking netwerkbandbreedte verbruikt. Dit terugkerende patroon wordt onthuld in de maandelijkse trend. Een jaarlijkse trend, zoals weergegeven in het voorbeeld, kan een te lange duur hebben om zinvolle prestatiegegevens over de baseline te geven. Het kan echter helpen om langetermijnpatronen te identificeren die verder moeten worden geanalyseerd. Gewoonlijk hoeft een baseline niet langer dan zes weken te duren, tenzij specifieke langetermijntrends moeten worden gemeten. Over het algemeen is een baseline van twee tot vier weken voldoende.
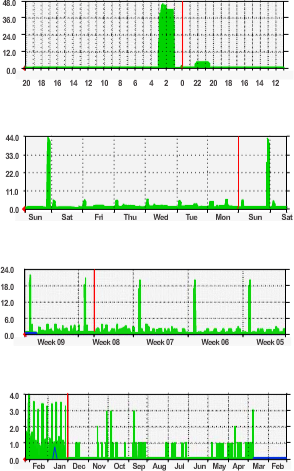
Baseline-metingen mogen niet worden uitgevoerd in tijden van unieke verkeerspatronen, omdat de gegevens een onnauwkeurig beeld zouden geven van de normale netwerkactiviteiten. Er moet regelmatig een baselineanalyse van het netwerk worden uitgevoerd. Voer een jaarlijkse analyse uit van het hele netwerk of baseline verschillende delen van het netwerk op een roterende basis. Er moet regelmatig een analyse worden uitgevoerd om te begrijpen hoe het netwerk wordt beïnvloed door groei en andere veranderingen.
9.1.1.5. Gegevens meten
Bij het documenteren van het netwerk is het vaak nodig om informatie rechtstreeks van routers en switches te verzamelen. Voor de hand liggende nuttige opdrachten voor netwerkdocumentatie zijn onder meer ping, traceroute en telnet, evenals de volgende show-opdrachten:
- De opdrachten show ip interface brief en show ipv6 interface short worden gebruikt om de status up of down en het IP-adres van alle interfaces op een apparaat weer te geven.
- De opdrachten show ip route en show ipv6 route worden gebruikt om de routeringstabel in een router weer te geven om de direct verbonden buren, meer afgelegen apparaten (via aangeleerde routes) en de geconfigureerde routeringsprotocollen te leren.
- De opdracht show cdp neighbor detail wordt gebruikt om gedetailleerde informatie te verkrijgen over direct verbonden Cisco-buurapparaten.
De volgende tabel geeft een overzicht van enkele van de meest voorkomende Cisco IOS-opdrachten die worden gebruikt voor het verzamelen van gegevens.
| Opdracht | Beschrijving |
|---|---|
| show version | Toont uptime, versie-informatie voor apparaatsoftware en hardware. |
| show ip interface[brief] show ipv6 interface[brief] | Toont alle configuratie-opties die op een interface zijn ingesteld. Gebruik het korte trefwoord om alleen de status omhoog/omlaag van IP-interfaces weer te geven en het IP-adres is van elke interface. |
| show interfaces [interface_type interface_num] | Toont gedetailleerde uitvoer voor elke interface. Om gedetailleerde uitvoer voor slechts een enkele interface weer te geven, neemt u het interfacetype en -nummer op in de opdracht (bijv. gigabitethernet 0/0). |
| show ip route show ipv6 route | Toont de inhoud van de routeringstabel. |
| show arp show ipv6 neighbors | Toont de inhoud van de ARP-tabel (IPv4) en de naburige tabel (IPv6). |
| show running-config | Toont de huidige configuratie. |
| show port | Toont de status van poorten op een switch. |
| show vlan | Toont de status van VLAN’s op een switch |
| show tech-support | Deze opdracht is handig voor het verzamelen van een grote hoeveelheid informatie over het apparaat voor het oplossen van problemen. Het voert meerdere show opdrachten uit die kunnen worden gegeven aan vertegenwoordigers van de technische ondersteuning bij het melden van een probleem. |
| show ip cache flow | Geeft een samenvatting weer van de NetFlow-boekhoudstatistieken. |
Handmatige gegevensverzameling met behulp van show opdrachten op individuele netwerkapparaten is extreem tijdrovend en is geen schaalbare oplossing. Het handmatig verzamelen van gegevens moet worden gereserveerd voor kleinere netwerken of worden beperkt tot bedrijfskritieke netwerkapparaten. Voor eenvoudigere netwerkontwerpen gebruiken basislijntaken doorgaans een combinatie van handmatige gegevensverzameling en eenvoudige netwerkprotocolinspecteurs.
Geavanceerde netwerkbeheersoftware wordt vaak gebruikt om grote en complexe netwerken te baselinen. Zoals weergegeven in afbeelding 2, stelt de Fluke Network SuperAgent-module beheerders in staat automatisch rapporten te maken en te beoordelen met behulp van de functie Intelligent Baselines. Deze functie vergelijkt de huidige prestatieniveaus met historische waarnemingen en kan automatisch prestatieproblemen en toepassingen identificeren die niet de verwachte serviceniveaus bieden.
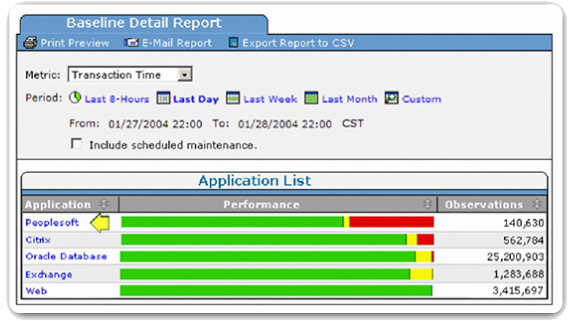
Het vaststellen van een initiële basislijn of het uitvoeren van een prestatiebewakingsanalyse kan vele uren of dagen vergen om de netwerkprestaties nauwkeurig weer te geven. Netwerkbeheersoftware of protocolinspecteurs en sniffers zijn vaak continu actief tijdens het gegevensverzamelingsproces.
9.1.2. Proces voor probleemoplossing
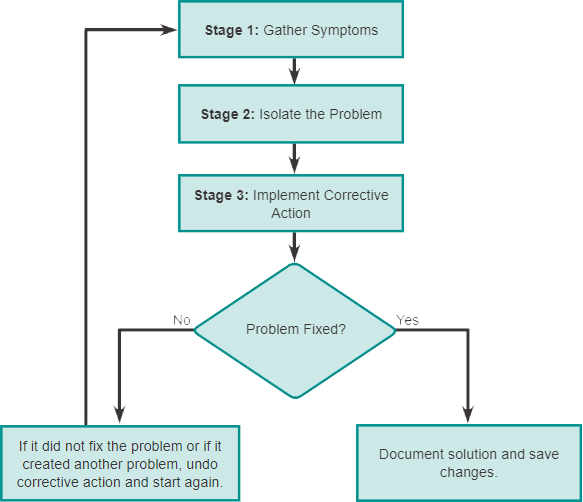
9.1.2.1. Algemene procedures voor probleemoplossing
Nadat alle symptomen zijn verzameld en als er geen oplossing is gevonden, vergelijkt de netwerkbeheerder de kenmerken van het probleem met de logische lagen van het netwerk om het probleem te isoleren en op te lossen.
Logische netwerkmodellen, zoals de OSI- en TCP/IP-modellen, scheiden netwerkfunctionaliteit in modulaire lagen. Deze gelaagde modellen kunnen worden toegepast op het fysieke netwerk om netwerkproblemen te isoleren bij het oplossen van problemen. Als de symptomen bijvoorbeeld wijzen op een fysiek verbindingsprobleem, kan de netwerktechnicus zich concentreren op het oplossen van problemen met het circuit dat op de fysieke laag werkt. Als dat circuit functioneert zoals verwacht, kijkt de technicus naar gebieden binnen een andere laag die het probleem zouden kunnen veroorzaken.
OSI-referentiemodel
Het OSI-referentiemodel biedt een gemeenschappelijke taal voor netwerkbeheerders en wordt vaak gebruikt bij het oplossen van problemen met netwerken. Problemen worden meestal beschreven in termen van een bepaalde OSI-modellaag.
Het OSI-referentiemodel beschrijft hoe informatie van een softwaretoepassing op de ene computer via een netwerkmedium naar een softwaretoepassing op een andere computer gaat.
De bovenste lagen (5 tot 7) van het OSI-model behandelen applicatieproblemen en worden over het algemeen alleen in software geïmplementeerd. De applicatielaag staat het dichtst bij de eindgebruiker. Zowel gebruikers als applicatielaagprocessen werken samen met softwareapplicaties die een communicatiecomponent bevatten.
De onderste lagen (1 tot 4) van het OSI-model behandelen problemen met gegevenstransport. Lagen 3 en 4 worden over het algemeen alleen in software geïmplementeerd. De fysieke laag (Laag 1) en datalinklaag (Laag 2) zijn geïmplementeerd in hardware en software. De fysieke laag zit het dichtst bij het fysieke netwerkmedium, zoals de netwerkbekabeling, en is verantwoordelijk voor het daadwerkelijk plaatsen van informatie op het medium.
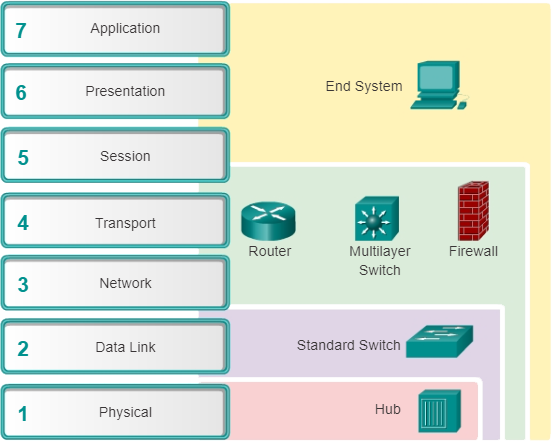
De volgende afbeelding toont enkele veelvoorkomende apparaten en de OSI-lagen die moeten worden onderzocht tijdens het probleemoplossingsproces voor dat apparaat. Merk op dat routers en meerlaagse switches worden weergegeven op laag 4, de transportlaag. Hoewel routers en meerlaagse switches meestal beslissingen nemen over het doorsturen van Layer 3, kunnen ACL’s op deze apparaten worden gebruikt om filterbeslissingen te nemen met behulp van Layer 4-informatie.
TCP/IP-model
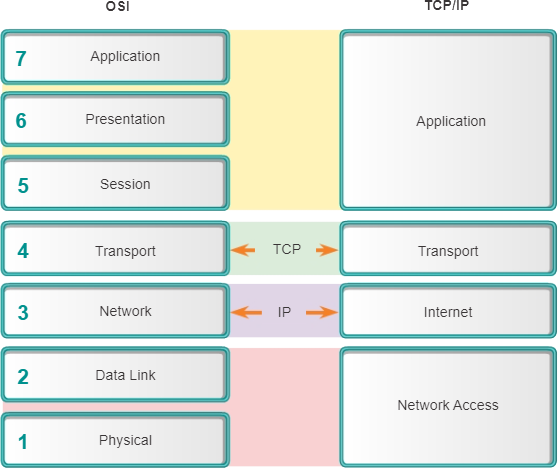
Net als het OSI-netwerkmodel verdeelt het TCP/IP-netwerkmodel de netwerkarchitectuur ook in modulaire lagen. Afbeelding 2 laat zien hoe het TCP/IP-netwerkmodel is gekoppeld aan de lagen van het OSI-netwerkmodel. Door deze nauwe mapping kan de TCP/IP-suite van protocollen met succes communiceren met zoveel netwerktechnologieën.
De applicatielaag in de TCP/IP-suite combineert eigenlijk de functies van de drie OSI-modellagen: sessie, presentatie en applicatie. De applicatielaag zorgt voor communicatie tussen applicaties, zoals FTP, HTTP en SMTP op aparte hosts.
De transportlagen van TCP/IP en OSI corresponderen direct in functie. De transportlaag is verantwoordelijk voor het uitwisselen van segmenten tussen apparaten op een TCP/IP-netwerk.
De TCP/IP-internetlaag heeft betrekking op de OSI-netwerklaag. De internetlaag is verantwoordelijk voor het plaatsen van berichten in een vast formaat waarmee apparaten ze kunnen verwerken.
De TCP/IP-netwerktoegangslaag komt overeen met de fysieke OSI- en datalinklagen. De netwerktoegangslaag communiceert rechtstreeks met de netwerkmedia en biedt een interface tussen de architectuur van het netwerk en de internetlaag.
9.1.2.2. Symptomen verzamelen
Bij het verzamelen van symptomen is het belangrijk dat de beheerder feiten en bewijzen verzamelt om mogelijke oorzaken geleidelijk te elimineren en uiteindelijk de hoofdoorzaak van het probleem te identificeren. Door de informatie te analyseren, formuleert de netwerkbeheerder een hypothese om mogelijke oorzaken en oplossingen voor te stellen en andere te elimineren.
Er zijn vijf stappen om informatie te verzamelen:
Stap 1. Verzamel informatie – Verzamel informatie van de probleemkaart, gebruikers of eindsystemen die door het probleem worden beïnvloed om een definitie van het probleem te vormen.
Stap 2. Bepaal het eigenaarschap – Als het probleem binnen de controle van de organisatie ligt, ga dan naar de volgende fase. Als het probleem buiten de controle van de organisatie ligt (bijvoorbeeld verloren internetverbinding buiten het autonome systeem), neem dan contact op met een beheerder van het externe systeem voordat u aanvullende netwerksymptomen verzamelt.
Stap 3. Beperk het bereik – Bepaal of het probleem zich in de kern, distributie of toegangslaag van het netwerk bevindt. Analyseer op de geïdentificeerde laag de bestaande symptomen en gebruik uw kennis van de netwerktopologie om te bepalen welk apparaat de meest waarschijnlijke oorzaak is.
Stap 4. Verzamel symptomen van verdachte apparaten – Gebruik een gelaagde aanpak voor probleemoplossing om hardware- en softwaresymptomen van de verdachte apparaten te verzamelen. Begin met de meest waarschijnlijke mogelijkheid en gebruik kennis en ervaring om te bepalen of het probleem eerder een hardware- of softwareconfiguratieprobleem is.
Stap 5. Documenteer symptomen – Soms kan het probleem worden opgelost met behulp van de gedocumenteerde symptomen. Als dat niet het geval is, begint u met de isolatiefase van het algemene proces voor probleemoplossing.
Gebruik Cisco IOS-opdrachten en andere hulpmiddelen om symptomen over het netwerk te verzamelen, zoals:
- ping-, traceroute- en telnet-opdrachten
- show en debug opdrachten
- packet opnames
- apparaatlogboeken
De volgende tabel beschrijft de gebruikelijke Cisco IOS-opdrachten die worden gebruikt om de symptomen van een netwerkprobleem te verzamelen.
| Opdracht | Beschrijving |
|---|---|
| ping {host|ip-address} | Verzendt een echo-verzoekpakket naar een adres en wacht vervolgens op een antwoord. De host | ip-address variabele is het IP-alias of IP-adres van het doelsysteem. |
| traceroute {destination} | Identificeert het pad dat een pakket door de netwerken neemt. De bestemmingsvariabele is de hostnaam of het IP-adres van het doelsysteem. |
| telnet {host|ip-address} | Maakt verbinding met een IP-adres met behulp van de Telnet-toepassing. |
| show ip interface brief show ipv6 interface brief | Geeft een samenvatting weer van de status van alle interfaces op een apparaat. |
| show ip route show ipv6 route | Geeft de huidige IPv4- en IPv6-routeringstabellen weer, die de routes naar alle bekende netwerkbestemmingen bevatten. |
| show running-config | Toont de inhoud van het huidige configuratiebestand. |
| [no] debug ? | Toont een lijst met opties voor het in- of uitschakelen van foutopsporingsgebeurtenissen op een apparaat. |
| show protocols | Toont de geconfigureerde protocollen en toont de globale en interfacespecifieke status van elk geconfigureerd Layer 3-protocol. |
Opmerking: hoewel het debug-commando een belangrijk hulpmiddel is voor het verzamelen van symptomen, genereert het een grote hoeveelheid consoleberichtenverkeer en kunnen de prestaties van een netwerkapparaat merkbaar worden beïnvloed. Als de foutopsporing tijdens normale werkuren moet worden uitgevoerd, waarschuw dan netwerkgebruikers dat er een probleemoplossing wordt uitgevoerd en dat de netwerkprestaties mogelijk worden beïnvloed. Vergeet niet om foutopsporing uit te schakelen als u klaar bent.
9.1.2.3. Eindgebruikers bevragen
In veel gevallen wordt het probleem gemeld door een eindgebruiker. De informatie kan vaak vaag of misleidend zijn, zoals “Het netwerk is uitgevallen” of “Ik heb geen toegang tot mijn e-mail”. In deze gevallen moet het probleem beter worden gedefinieerd. Hiervoor kan het nodig zijn om vragen te stellen aan de eindgebruikers.
Gebruik effectieve ondervragingstechnieken wanneer u de eindgebruikers vraagt naar een netwerkprobleem dat ze mogelijk ervaren. Dit zal u helpen om de informatie te krijgen die nodig is om de symptomen van een probleem te documenteren. De onderstaande tabel geeft enkele richtlijnen en voorbeeldvragen voor eindgebruikers.
| Richtlijnen | Voorbeeldvragen van eindgebruikers |
|---|---|
| Stel vragen die relevant zijn voor het probleem. | Wat werkt niet? |
| Gebruik elke vraag als een middel om mogelijke problemen op te lossen of te ontdekken. | Zijn de dingen die wel werken en de dingen die niet werken gerelateerd? |
| Spreek op een technisch niveau dat de gebruiker kan begrijpen. | Heeft het ding dat niet werkt ooit gewerkt? |
| Vraag de gebruiker wanneer het probleem voor het eerst werd opgemerkt. | Wanneer werd het probleem voor het eerst opgemerkt? |
| Is er iets ongewoons gebeurd sinds de laatste keer dat het werkte? | Wat is er veranderd sinds de laatste keer dat het werkte? |
| Vraag de gebruiker om het probleem opnieuw te creëren, indien mogelijk. | Kun je het probleem reproduceren? |
| Bepaal de volgorde van gebeurtenissen die plaatsvonden voordat het probleem zich voordeed. | Wanneer doet het probleem zich precies voor? |
9.1.3. Het probleem isoleren met behulp van gelaagde modellen
9.1.3.1. Gelaagde modellen gebruiken voor probleemoplossing
Nadat alle symptomen zijn verzameld en als er geen oplossing is gevonden, vergelijkt de netwerkbeheerder de kenmerken van het probleem met de logische lagen van het netwerk om het probleem te isoleren en op te lossen.
Logische netwerkmodellen, zoals de OSI- en TCP/IP-modellen, scheiden netwerkfunctionaliteit in modulaire lagen. Deze gelaagde modellen kunnen worden toegepast op het fysieke netwerk om netwerkproblemen te isoleren bij het oplossen van problemen. Als de symptomen bijvoorbeeld wijzen op een fysiek verbindingsprobleem, kan de netwerktechnicus zich concentreren op het oplossen van problemen met het circuit dat op de fysieke laag werkt. Als dat circuit functioneert zoals verwacht, kijkt de technicus naar gebieden binnen een andere laag die het probleem zouden kunnen veroorzaken.
OSI-referentiemodel
Het OSI-referentiemodel biedt een gemeenschappelijke taal voor netwerkbeheerders en wordt vaak gebruikt bij het oplossen van problemen met netwerken. Problemen worden meestal beschreven in termen van een bepaalde OSI-modellaag.
Het OSI-referentiemodel beschrijft hoe informatie van een softwaretoepassing op de ene computer via een netwerkmedium naar een softwaretoepassing op een andere computer gaat.
De bovenste lagen (5 tot 7) van het OSI-model behandelen applicatieproblemen en worden over het algemeen alleen in software geïmplementeerd. De applicatielaag staat het dichtst bij de eindgebruiker. Zowel gebruikers als applicatielaagprocessen werken samen met softwareapplicaties die een communicatiecomponent bevatten.
De onderste lagen (1 tot 4) van het OSI-model behandelen problemen met gegevenstransport. Lagen 3 en 4 worden over het algemeen alleen in software geïmplementeerd. De fysieke laag (Laag 1) en datalinklaag (Laag 2) zijn geïmplementeerd in hardware en software. De fysieke laag zit het dichtst bij het fysieke netwerkmedium, zoals de netwerkbekabeling, en is verantwoordelijk voor het daadwerkelijk plaatsen van informatie op het medium.
De volgende afbeelding toont enkele veelvoorkomende apparaten en de OSI-lagen die moeten worden onderzocht tijdens het probleemoplossingsproces voor dat apparaat. Merk op dat routers en meerlaagse switches worden weergegeven op laag 4, de transportlaag. Hoewel routers en meerlaagse switches meestal beslissingen nemen over het doorsturen van Layer 3, kunnen ACL’s op deze apparaten worden gebruikt om filterbeslissingen te nemen met behulp van Layer 4-informatie.
TCP/IP-model
Net als het OSI-netwerkmodel verdeelt het TCP/IP-netwerkmodel de netwerkarchitectuur ook in modulaire lagen. De volgende afbeelding laat zien hoe het TCP/IP-netwerkmodel is gekoppeld aan de lagen van het OSI-netwerkmodel. Door deze nauwe mapping kan de TCP/IP-suite van protocollen met succes communiceren met zoveel netwerktechnologieën.
De applicatielaag in de TCP/IP-suite combineert eigenlijk de functies van de drie OSI-modellagen: sessie, presentatie en applicatie. De applicatielaag zorgt voor communicatie tussen applicaties, zoals FTP, HTTP en SMTP op aparte hosts.
De transportlagen van TCP/IP en OSI corresponderen direct in functie. De transportlaag is verantwoordelijk voor het uitwisselen van segmenten tussen apparaten op een TCP/IP-netwerk.
De TCP/IP-internetlaag heeft betrekking op de OSI-netwerklaag. De internetlaag is verantwoordelijk voor het plaatsen van berichten in een vast formaat waarmee apparaten ze kunnen verwerken.
De TCP/IP-netwerktoegangslaag komt overeen met de fysieke OSI- en datalinklagen. De netwerktoegangslaag communiceert rechtstreeks met de netwerkmedia en biedt een interface tussen de architectuur van het netwerk en de internetlaag.
9.1.3.2. Methoden voor probleemoplossing
Met behulp van de gelaagde modellen zijn er drie primaire methoden voor het oplossen van problemen met netwerken:
- Bottom-Up
- To-Down
- Divide-and-conquer
Elke aanpak heeft zijn voor- en nadelen. In dit onderwerp worden de drie methoden beschreven en worden richtlijnen gegeven voor het kiezen van de beste methode voor een specifieke situatie.
Bottom-Up methode voor probleemoplossing
Bij bottom-up troubleshooting begin je met de fysieke componenten van het netwerk en ga je omhoog door de lagen van het OSI-model totdat de oorzaak van het probleem is geïdentificeerd, zoals weergegeven in de volgende figuur. Bottom-up troubleshooting is een goede benadering om te gebruiken wanneer wordt vermoed dat het een fysiek probleem is. De meeste netwerkproblemen bevinden zich op de lagere niveaus, dus het implementeren van de bottom-upbenadering is vaak effectief.
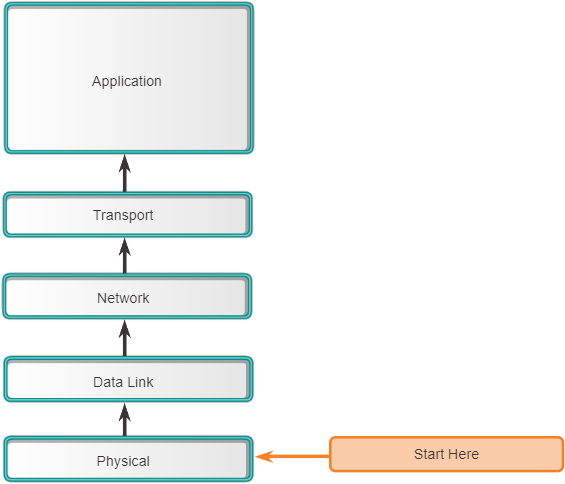
Het nadeel van de bottom-up aanpak voor probleemoplossing is dat u elk apparaat en elke interface op het netwerk moet controleren totdat de mogelijke oorzaak van het probleem is gevonden. Onthoud dat elke conclusie en mogelijkheid moet worden gedocumenteerd, dus er kan veel papierwerk bij deze benadering komen kijken. Een andere uitdaging is om te bepalen welke apparaten als eerste moeten worden onderzocht.
Top-Down methode voor probleemoplossing
In figuur 2 begint de probleemoplossing van bovenaf bij de toepassingen van de eindgebruiker en gaat door de lagen van het OSI-model totdat de oorzaak van het probleem is vastgesteld. Toepassingen van eindgebruikers van een eindsysteem worden getest voordat de meer specifieke netwerkonderdelen worden aangepakt. Gebruik deze aanpak voor eenvoudigere problemen, of wanneer u denkt dat het probleem bij een stukje software ligt.
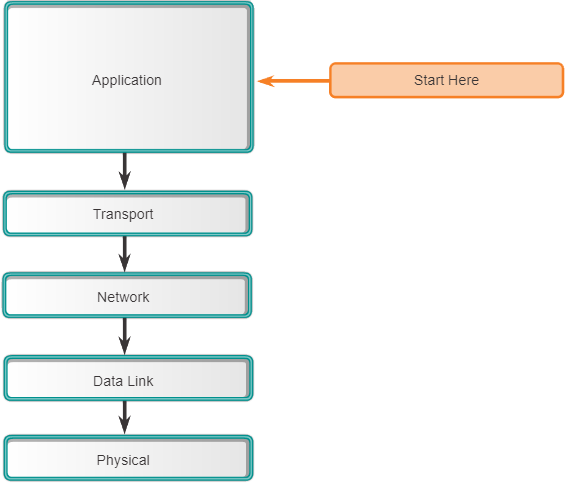
Het nadeel van de top-down benadering is dat elke netwerktoepassing moet worden gecontroleerd totdat de mogelijke oorzaak van het probleem is gevonden. Elke conclusie en mogelijkheid moet worden gedocumenteerd. De uitdaging is om te bepalen welke aanvraag als eerste moet worden onderzocht.
Divide-and-Conquer-methode voor probleemoplossing
De volgende afbeelding toont de verdeel-en-heers-aanpak voor het oplossen van een netwerkprobleem. De netwerkbeheerder selecteert een laag en test vanuit die laag in beide richtingen.
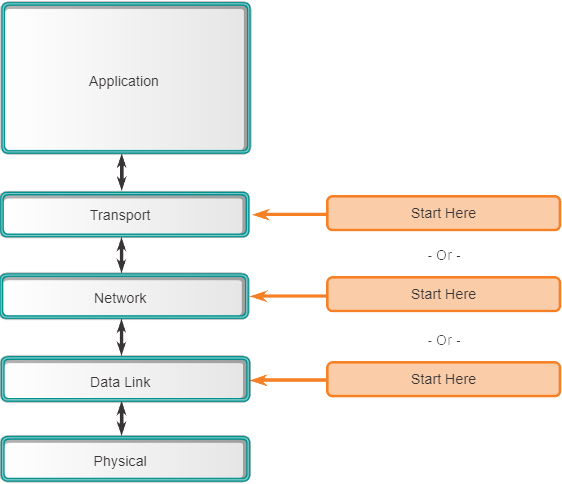
Bij het oplossen van problemen met verdeel-en-heers begint u met het verzamelen van gebruikerservaringen van het probleem, documenteert u de symptomen en maakt u vervolgens, met behulp van die informatie, een weloverwogen gok over welke OSI-laag uw onderzoek moet beginnen. Wanneer is geverifieerd dat een laag goed functioneert, kan worden aangenomen dat de onderliggende lagen functioneren. De beheerder kan de OSI-lagen opwerken. Als een OSI-laag niet goed functioneert, kan de beheerder het OSI-laagmodel afbouwen.
Als gebruikers bijvoorbeeld geen toegang hebben tot de webserver, maar wel de server kunnen pingen, ligt het probleem boven laag 3. Als het pingen van de server niet lukt, ligt het probleem waarschijnlijk op een lagere OSI-laag.
Naast de systematische, gelaagde aanpak van probleemoplossing, zijn er ook minder gestructureerde aanpak voor probleemoplossing.
Een aanpak voor het oplossen van problemen is gebaseerd op een weloverwogen schatting door de netwerkbeheerder, op basis van de symptomen van het probleem. Deze methode wordt met meer succes geïmplementeerd door ervaren netwerkbeheerders, omdat ervaren netwerkbeheerders vertrouwen op hun uitgebreide kennis en ervaring om netwerkproblemen resoluut te isoleren en op te lossen. Met een minder ervaren netwerkbeheerder kan deze methode voor probleemoplossing meer lijken op willekeurige probleemoplossing.
Een andere benadering is het vergelijken van een werk- en niet-werksituatie en het opsporen van significante verschillen, waaronder:
- Configuraties
- Softwareversies
- Hardware en andere apparaateigenschappen
Het gebruik van deze methode kan leiden tot een werkende oplossing, maar zonder duidelijk de oorzaak van het probleem te onthullen. Deze methode kan handig zijn wanneer de netwerkbeheerder geen expertise heeft, of wanneer het probleem snel moet worden opgelost. Nadat de fix is geïmplementeerd, kan de netwerkbeheerder verder onderzoek doen naar de werkelijke oorzaak van het probleem.
Vervanging is een andere methode voor snelle probleemoplossing. Het gaat om het verwisselen van het problematische apparaat met een bekend, werkend apparaat. Als het probleem is verholpen, weet de netwerkbeheerder dat het probleem bij het verwijderde apparaat ligt. Als het probleem blijft bestaan, kan de oorzaak ergens anders liggen. In specifieke situaties kan dit een ideale methode zijn om problemen snel op te lossen, zoals wanneer een kritiek single point of failure, zoals een grensrouter, uitvalt. Het kan voordeliger zijn om het apparaat eenvoudig te vervangen en de service te herstellen, in plaats van het probleem op te lossen.
9.1.3.3. Richtlijnen voor het selecteren van een methode voor probleemoplossing
Om netwerkproblemen snel op te lossen, moet u de tijd nemen om de meest effectieve methode voor het oplossen van netwerkproblemen te selecteren. De figuur illustreert dit proces.
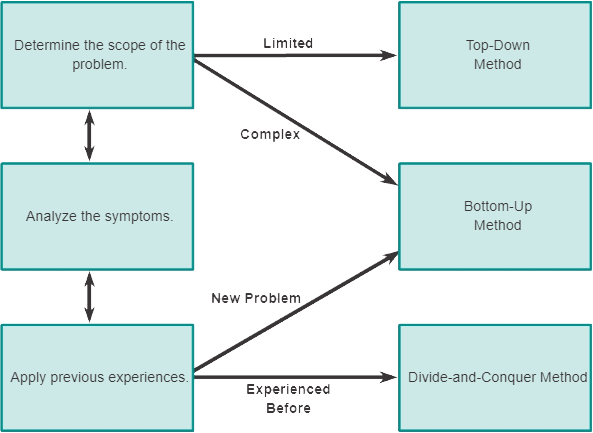
Hieronder volgt een voorbeeld van hoe u een methode voor probleemoplossing kiest op basis van een specifiek probleem:
Twee IP-routers wisselen geen routeringsinformatie uit. De laatste keer dat dit type probleem zich voordeed, was een protocolprobleem. Kies daarom voor de verdeel-en-heers-methode voor probleemoplossing. Uit analyse blijkt dat er connectiviteit is tussen de routers. Start het probleemoplossingsproces op de fysieke of datalinklaag. Bevestig de connectiviteit en begin met het testen van de TCP/IP-gerelateerde functies op de volgende laag in het OSI-model, de netwerklaag.
9.2. Scenario’s voor probleemoplossing
9.2.1. Hulpprogramma’s voor probleemoplossing
9.2.1.1. Hulpprogramma’s voor het oplossen van software
Er is een grote verscheidenheid aan software- en hardwaretools beschikbaar om het oplossen van problemen gemakkelijker te maken. Deze tools kunnen worden gebruikt om symptomen van netwerkproblemen te verzamelen en te analyseren. Ze bieden vaak monitoring- en rapportagefuncties die kunnen worden gebruikt om de netwerkbasislijn vast te stellen.
Veelgebruikte hulpprogramma’s voor het oplossen van softwareproblemen zijn onder meer:
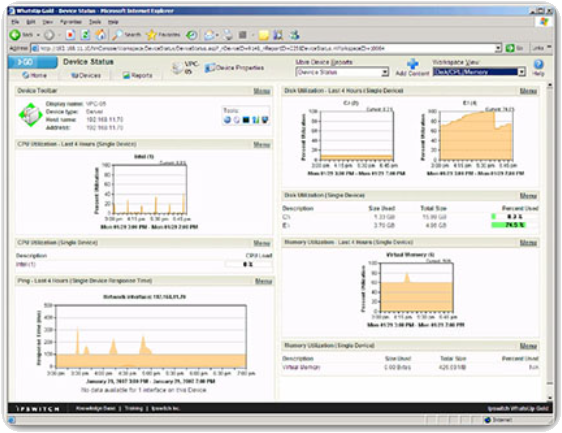
Hulpprogramma’s voor netwerkbeheersysteem
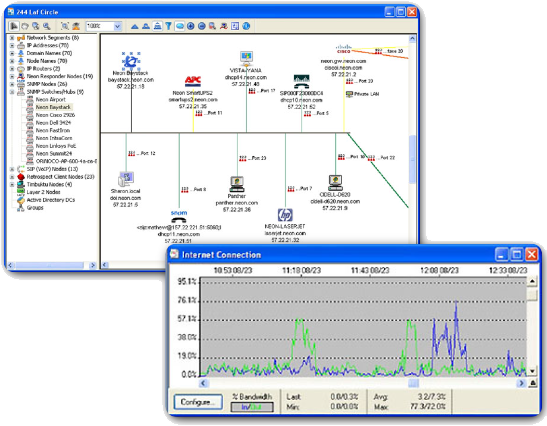
Hulpprogramma’s voor netwerkbeheersystemen (NMS) omvatten hulpmiddelen voor bewaking, configuratie en foutbeheer op apparaatniveau. De volgende afbeelding toont een voorbeeldweergave van de “WhatsUp Gold” NMS-software. Deze tools kunnen worden gebruikt om netwerkproblemen te onderzoeken en op te lossen. Software voor netwerkbewaking geeft grafisch een fysieke weergave van netwerkapparaten weer, zodat netwerkbeheerders externe apparaten kunnen bewaken zonder ze fysiek te controleren. Apparaatbeheersoftware biedt dynamische status-, statistieken en configuratie-informatie voor geschakelde producten. Voorbeelden van andere veelgebruikte netwerkbeheertools zijn CiscoView, HPBTO Software (voorheen OpenView) en SolarWinds.
Kennisbanken
Online kennisbanken van leveranciers van netwerkapparatuur zijn onmisbare informatiebronnen geworden. Wanneer leveranciersgebaseerde kennisbanken worden gecombineerd met internetzoekmachines zoals Google, heeft een netwerkbeheerder toegang tot een enorme hoeveelheid op ervaring gebaseerde informatie.
De onderstaande afbeelding toont de pagina Cisco Tools & Resources op http://www.cisco.com. Dit is een gratis tool die informatie geeft over Cisco-gerelateerde hardware en software. Het bevat procedures voor probleemoplossing, implementatiehandleidingen en originele whitepapers over de meeste aspecten van netwerktechnologie.
Basishulpmiddelen
Er zijn veel tools beschikbaar voor het automatiseren van de netwerkdocumentatie en het basislijnproces. Deze tools zijn beschikbaar voor Windows-, Linux- en AUX-besturingssystemen. De volgende afbeelding toont een schermopname van de SolarWinds LANsurveyor- en CyberGauge-software. Hulpprogramma’s voor basislijnen helpen bij veelvoorkomende documentatietaken. Ze kunnen bijvoorbeeld netwerkdiagrammen tekenen, de netwerksoftware en hardwaredocumentatie up-to-date houden en helpen om op een kosteneffectieve manier het bandbreedtegebruik van het basisnetwerk te meten.
Host-gebaseerde protocolanalysers
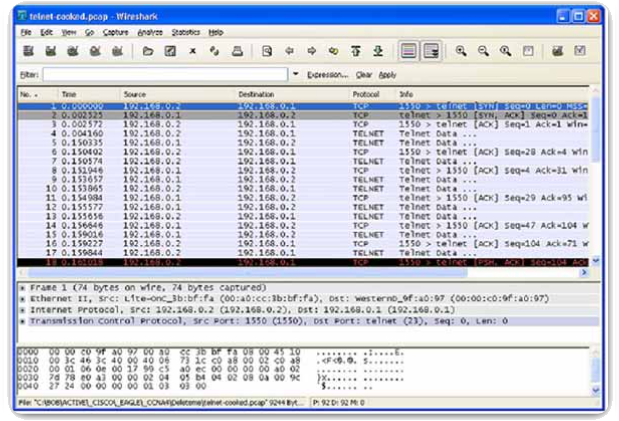
Een protocolanalysator decodeert de verschillende protocollagen in een opgenomen frame en presenteert deze informatie in een relatief eenvoudig te gebruiken formaat. De volgende afbeelding toont een schermopname van de Wireshark-protocolanalysator. De informatie die wordt weergegeven door een protocolanalysator omvat de fysieke, datalink, protocol en beschrijvingen voor elk frame. De meeste protocolanalysers kunnen verkeer filteren dat aan bepaalde criteria voldoet, zodat bijvoorbeeld al het verkeer van en naar een bepaald apparaat kan worden vastgelegd. Protocolanalysatoren zoals Wireshark kunnen helpen bij het oplossen van problemen met netwerkprestaties. Het is belangrijk om zowel een goed begrip te hebben van het gebruik van de protocolanalysator als van TCP/IP. Om meer kennis en vaardigheid te krijgen met Wireshark, is een uitstekende bron http://www.wiresharkbook.com.
Cisco IOS Embedded Packet Capture
De Cisco IOS Embedded Packet Capture (EPC) levert een krachtige tool voor probleemoplossing en tracering. Met deze functie kunnen netwerkbeheerders IPv4- en IPv6-pakketten vastleggen die door, naar en van een Cisco-router stromen. De Cisco IOS EPC-functie wordt voornamelijk gebruikt in scenario’s voor het oplossen van problemen, waarbij het handig is om de werkelijke gegevens te zien die door, van of naar het netwerkapparaat worden verzonden.
Medewerkers van de supportdesk moeten bijvoorbeeld bepalen waarom een bepaald apparaat geen toegang heeft tot het netwerk of een bepaalde applicatie. Het kan nodig zijn om IP-gegevenspakketten vast te leggen en de gegevens te onderzoeken om het probleem te ontdekken. Een ander voorbeeld is het bepalen van een aanvalssignatuur voor een netwerkbedreiging of een inbreuk op de serversysteembeveiliging. De Cisco IOS EPC kan helpen bij het vastleggen van pakketten die het netwerk binnenkomen bij de oorsprong of perimeter.
De Cisco IOS EPC is handig wanneer een netwerkprotocolanalysator nuttig kan zijn bij het opsporen van fouten, maar wanneer het niet praktisch is om zo’n apparaat te installeren.
Raadpleeg de Embedded Packet Capture Configuration Guide voor meer informatie over het gebruik en de configuratie van Cisco EPC.
9.2.1.2. Hardware hulpmiddelen voor het oplossen van problemen
Veelgebruikte hulpprogramma’s voor het oplossen van hardwareproblemen zijn onder meer:
- Netwerkanalysemodule – Zoals weergegeven kan een netwerkanalysemodule (NAM) worden geïnstalleerd in Cisco Catalyst 6500-serie switches en Cisco 7600-serie routers. NAM’s bieden een grafische weergave van verkeer van lokale en externe switches en routers. De NAM is een ingebouwde browsergebaseerde interface die rapporten genereert over het verkeer dat kritieke netwerkbronnen verbruikt. Bovendien kan de NAM pakketten vastleggen en decoderen en responstijden volgen om een applicatieprobleem op het netwerk of de server te lokaliseren.
- Digitale multimeters – Digitale multimeters (DMM’s), zoals de Fluke 179, zijn testinstrumenten die worden gebruikt om rechtstreeks elektrische waarden van spanning, stroom en weerstand te meten. Bij het oplossen van problemen met netwerken omvatten de meeste multimediatests het controleren van de spanningsniveaus van de voeding en het verifiëren of netwerkapparaten stroom krijgen.
- Kabeltesters – Kabeltesters zijn gespecialiseerde, draagbare apparaten die zijn ontworpen voor het testen van de verschillende soorten datacommunicatiebekabeling. Kabeltesters kunnen worden gebruikt om gebroken draden, gekruiste bedrading, kortgesloten verbindingen en onjuist gepaarde verbindingen te detecteren. Deze apparaten kunnen goedkope continuïteitstesters, redelijk geprijsde databekabelingstesters of dure tijddomeinreflectometers (TDR’s) zijn. TDR’s worden gebruikt om de afstand tot een kabelbreuk te bepalen. Deze apparaten sturen signalen langs de kabel en wachten tot ze worden weerkaatst. De tijd tussen het verzenden en ontvangen van het signaal wordt omgezet in een afstandsmeting. De TDR-functie wordt normaal gesproken geleverd met databekabelingstesters. TDR’s die worden gebruikt om glasvezelkabels te testen, staan bekend als optische tijddomeinreflectometers (OTDR’s).
- Kabelanalysers – Kabelanalysers, zoals de Fluke DTX-kabelanalyser, zijn multifunctionele draagbare apparaten die worden gebruikt voor het testen en certificeren van koper- en glasvezelkabels voor verschillende services en normen. De meer geavanceerde tools omvatten geavanceerde diagnostische diagnostiek voor het meten van de afstand tot prestatiedefecten (NEXT, RL), het identificeren van corrigerende acties en het grafisch weergeven van overspraak- en impedantiegedrag. Kabelanalysatoren bevatten doorgaans ook pc-gebaseerde software. Nadat veldgegevens zijn verzameld, kan het handheld-apparaat zijn gegevens uploaden om up-to-date rapporten te maken.
- Draagbare netwerkanalysatoren – Draagbare apparaten zoals de Fluke OptiView worden gebruikt voor het oplossen van problemen met geschakelde netwerken en VLAN’s. Door de netwerkanalysator overal op het netwerk aan te sluiten, kan een netwerkingenieur de switchpoort zien waarop het apparaat is aangesloten, en het gemiddelde en piekgebruik. De analyser kan ook worden gebruikt om VLAN-configuratie te ontdekken, topnetwerkpraters te identificeren, netwerkverkeer te analyseren en interfacedetails te bekijken. Het apparaat kan doorgaans worden uitgevoerd naar een pc waarop netwerkbewakingssoftware is geïnstalleerd voor verdere analyse en probleemoplossing.
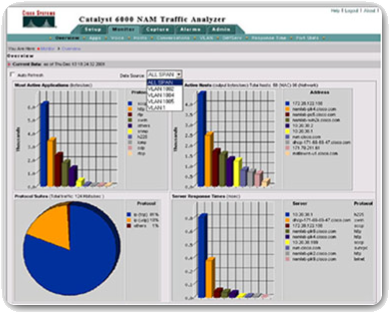
Web-Based Application Displays NAM Traffic Analyzer Data 
NAM Module for a Catalyst 6500 
Fluke 179 Digital Multimeter 
Fluke Networks LinkRunner Pro Tester 
Fluke Networks CableIQ Qualification Tester 
Fluke Networks DTX Cable Analyzer 
Fluke Networks OptiView™ Series III Integrated Network Analyzer
9.2.1.3. Probleemoplossing met behulp van een Syslog server
Syslog is een eenvoudig protocol dat door een IP-apparaat, een syslog-client, wordt gebruikt om op tekst gebaseerde logberichten naar een ander IP-apparaat, de syslog-server, te verzenden. Syslog is momenteel gedefinieerd in RFC 5424.
Het implementeren van een logboekfunctie is een belangrijk onderdeel van de netwerkbeveiliging en voor het oplossen van problemen met het netwerk. Cisco-apparaten kunnen informatie registreren over configuratiewijzigingen, ACL-overtredingen, interfacestatus en vele andere soorten gebeurtenissen. Cisco-apparaten kunnen logberichten naar verschillende faciliteiten verzenden. Gebeurtenisberichten kunnen worden verzonden naar een of meer van de volgende:
- Console – Console-logboekregistratie is standaard ingeschakeld. Berichten loggen in op de console en kunnen worden bekeken bij het wijzigen of testen van de router of switch met behulp van terminalemulatiesoftware terwijl deze is aangesloten op de consolepoort van de router.
- Terminallijnen – Ingeschakelde EXEC-sessies kunnen worden geconfigureerd om logberichten op alle terminallijnen te ontvangen. Net als bij console-logging, wordt dit type logging niet opgeslagen door de router en is daarom alleen waardevol voor de gebruiker op die lijn.
- Gebufferde logboekregistratie – Gebufferde logboekregistratie is iets nuttiger als hulpmiddel voor het oplossen van problemen, omdat logboekberichten een tijdje in het geheugen worden opgeslagen. Logboekberichten worden echter gewist wanneer het apparaat opnieuw wordt opgestart.
- SNMP-traps – Bepaalde drempels kunnen vooraf worden geconfigureerd op routers en andere apparaten. Routergebeurtenissen, zoals het overschrijden van een drempel, kunnen door de router worden verwerkt en als SNMP-traps worden doorgestuurd naar een externe SNMP-server. SNMP-traps zijn een levensvatbare faciliteit voor het loggen van beveiliging, maar vereisen de configuratie en het onderhoud van een SNMP-systeem.
- Syslog – Cisco-routers en -switches kunnen worden geconfigureerd om logberichten door te sturen naar een externe syslog-service. Deze service kan zich op een willekeurig aantal servers of werkstations bevinden, inclusief Microsoft Windows- en Linux-gebaseerde systemen. Syslog is de meest populaire voorziening voor het loggen van berichten, omdat het logboekopslag op lange termijn mogelijk maakt en een centrale locatie biedt voor alle routerberichten.
Cisco IOS-logberichten vallen in een van de acht niveaus, weergegeven in afbeelding 1. Hoe lager het niveau, hoe hoger het ernstniveau. Standaard worden alle berichten van niveau 0 tot 7 gelogd op de console. Hoewel de mogelijkheid om logboeken op een centrale syslog-server te bekijken, handig is bij het oplossen van problemen, kan het doorzoeken van een grote hoeveelheid gegevens een overweldigende taak zijn. De opdracht logging trap level beperkt berichten die zijn vastgelegd op de syslog-server op basis van de ernst. Het niveau is de naam of het nummer van het ernstniveau. Alleen berichten gelijk aan of numeriek lager dan het opgegeven niveau worden gelogd.
| Niveau | Sleutelwoord | Beschrijving | Definitie |
|---|---|---|---|
| 0 | emergencies | Systeem is onbruikbaar | LOG_EMERG |
| 1 | alerts | Onmiddellijke actie is nodig | LOG_ALERT |
| 2 | critical | Er zijn kritieke omstandigheden | LOG_CRIT |
| 3 | errors | Er zijn foutcondities | LOG_ERR |
| 4 | warnings | Er zijn waarschuwingsvoorwaarden | LOG_WARNING |
| 5 | notifications | Normale maar significante toestand | LOG_NOTICE |
| 6 | informational | Alleen informatieve berichten | LOG_INFO |
| 7 | debugging | Foutenopsporingsberichten | LOG_DEBUG |
In het voorbeeld in Afbeelding 2 worden systeemberichten van niveau 0 (noodgevallen) tot 5 (meldingen) naar de syslog-server gestuurd op 209.165.200.225.
R1(config)# logging host 209.165.200.225
R1(config)# logging trap notifications
R1(config)# logging on
9.2.2. Symptomen en oorzaken van netwerkproblemen oplossen
9.2.2.1. Problemen met de fysieke laag oplossen
De fysieke laag verzendt bits van de ene computer naar de andere en regelt de overdracht van een stroom bits over het fysieke medium. De fysieke laag is de enige laag met fysiek tastbare eigenschappen, zoals draden, kaarten en antennes.
Problemen op een netwerk presenteren zich vaak als prestatieproblemen. Prestatieproblemen betekenen dat er een verschil is tussen het verwachte gedrag en het waargenomen gedrag, en dat het systeem niet functioneert zoals redelijkerwijs verwacht mag worden. Storingen en suboptimale omstandigheden op de fysieke laag zijn niet alleen lastig voor gebruikers, maar kunnen de productiviteit van het hele bedrijf beïnvloeden. Netwerken die dit soort omstandigheden ervaren, sluiten meestal af. Omdat de bovenste lagen van het OSI-model afhankelijk zijn van de fysieke laag om te kunnen functioneren, moet een netwerkbeheerder in staat zijn om problemen op deze laag effectief te isoleren en te corrigeren.
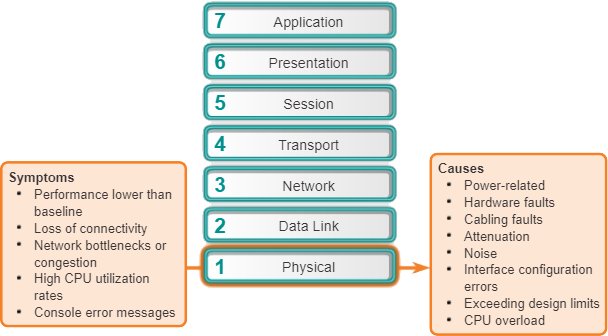
Veelvoorkomende symptomen van netwerkproblemen op de fysieke laag zijn:
- Prestaties lager dan baseline – De meest voorkomende redenen voor trage of slechte prestaties zijn onder meer overbelaste of te weinig krachtige servers, ongeschikte switch- of routerconfiguraties, verkeersopstoppingen op een link met lage capaciteit en chronisch frameverlies.
- Verlies van connectiviteit – Als een kabel of apparaat uitvalt; het meest voor de hand liggende symptoom is een verlies van connectiviteit tussen de apparaten die communiceren via die link of met het defecte apparaat of de defecte interface. Dit wordt aangegeven door een eenvoudige ping-test. Intermitterend verlies van connectiviteit kan wijzen op een losse of geoxideerde verbinding.
- Netwerkknelpunten of congestie – Als een router, interface of kabel uitvalt, kunnen routeringsprotocollen het verkeer omleiden naar andere routes die niet zijn ontworpen om de extra capaciteit te vervoeren. Dit kan leiden tot congestie of knelpunten in die delen van het netwerk.
- Hoge CPU-gebruikspercentages – Hoge CPU-gebruikspercentages zijn een symptoom dat een apparaat, zoals een router, switch of server, op de ontwerplimieten werkt of deze overschrijdt. Als het niet snel wordt aangepakt, kan overbelasting van de CPU ertoe leiden dat een apparaat wordt afgesloten of defect raakt.
- Consolefoutberichten – Foutberichten die op de apparaatconsole worden gerapporteerd, duiden op een probleem met de fysieke laag.
Problemen die vaak netwerkproblemen veroorzaken op de fysieke laag zijn onder meer:
- Stroomgerelateerd – Stroomgerelateerde problemen zijn de meest fundamentele reden voor netwerkstoringen. Controleer ook de werking van de ventilatoren en zorg ervoor dat de in- en uitlaatopeningen van het chassis vrij zijn. Als andere apparaten in de buurt ook zijn uitgeschakeld, vermoed dan een stroomstoring bij de hoofdvoeding.
- Hardwarefouten – Defecte netwerkinterfacekaarten (NIC’s) kunnen de oorzaak zijn van netwerktransmissiefouten als gevolg van late botsingen, korte frames en jabber. Jabber wordt vaak gedefinieerd als de toestand waarin een netwerkapparaat voortdurend willekeurige, nietszeggende gegevens naar het netwerk verzendt. Andere waarschijnlijke oorzaken van jabber zijn defecte of corrupte NIC-stuurprogrammabestanden, slechte bekabeling of aardingsproblemen.
- Bekabelingsfouten – Veel problemen kunnen worden verholpen door kabels die gedeeltelijk zijn losgeraakt, eenvoudig opnieuw aan te sluiten. Let bij het uitvoeren van een fysieke inspectie op beschadigde kabels, onjuiste kabeltypes en slecht gekrompen RJ-45’s. Verdachte kabels dienen getest of vervangen te worden met een bekende werkende kabel.
- Verzwakking – Verzwakking kan worden veroorzaakt als een kabellengte de ontwerplimiet voor de media overschrijdt, of wanneer er een slechte verbinding is als gevolg van een losse kabel of vuile of geoxideerde contacten. Als de verzwakking ernstig is, kan het ontvangende apparaat de componentbits van de stream niet altijd met succes van elkaar onderscheiden.
- Ruis – Lokale elektromagnetische interferentie (EMI) is algemeen bekend als ruis. Ruis kan worden gegenereerd door vele bronnen, zoals FM-radiostations, politieradio, beveiliging van gebouwen en avionica voor automatische landingen, overspraak (lawaai veroorzaakt door andere kabels in hetzelfde pad of aangrenzende kabels), elektrische kabels in de buurt, apparaten met grote elektrische motoren, of iets dat een zender bevat die krachtiger is dan een mobiele telefoon.
- Interfaceconfiguratiefouten – Veel dingen kunnen verkeerd worden geconfigureerd op een interface waardoor deze uitvalt, zoals een onjuiste kloksnelheid, een onjuiste klokbron en het niet inschakelen van de interface. Dit veroorzaakt een verlies van connectiviteit met aangesloten netwerksegmenten.
- Overschrijding van ontwerplimieten – Een onderdeel werkt mogelijk niet optimaal op de fysieke laag omdat het met een hogere gemiddelde snelheid wordt gebruikt dan waarvoor het is geconfigureerd. Bij het oplossen van dit soort problemen wordt het duidelijk dat de bronnen voor het apparaat op of in de buurt van de maximale capaciteit werken en is er een toename van het aantal interfacefouten.
- CPU-overbelasting – Symptomen zijn onder meer processen met hoge CPU-gebruikspercentages, dalingen van de invoerwachtrij, trage prestaties, routerservices zoals Telnet en ping zijn traag of reageren niet, of er zijn geen routeringsupdates. Een van de oorzaken van CPU-overbelasting in een router is veel verkeer. Als sommige interfaces regelmatig worden overbelast met verkeer, overweeg dan om de verkeersstroom in het netwerk opnieuw te ontwerpen of de hardware te upgraden.
9.2.2.2. Problemen met de datalinklaag oplossen
Problemen met Layer 2-problemen oplossen kan een uitdagend proces zijn. De configuratie en werking van deze protocollen zijn van cruciaal belang voor het creëren van een functioneel, goed afgestemd netwerk. Laag 2-problemen veroorzaken specifieke symptomen die, wanneer ze worden herkend, helpen het probleem snel te identificeren.
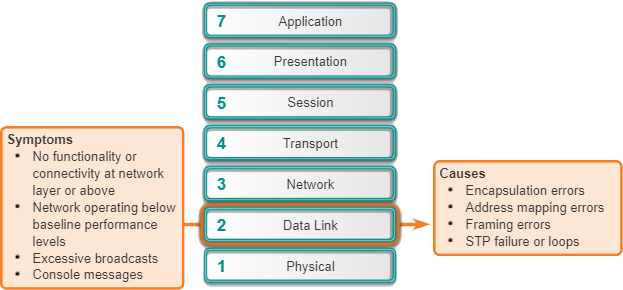
Veelvoorkomende symptomen van netwerkproblemen in de datalinklaag zijn:
- Geen functionaliteit of connectiviteit op de netwerklaag of daarboven – Sommige Layer 2-problemen kunnen de uitwisseling van frames via een link stoppen, terwijl andere er alleen maar voor zorgen dat de netwerkprestaties achteruitgaan.
- Het netwerk werkt onder het prestatieniveau van de basislijn – Er zijn twee verschillende typen suboptimale Layer 2-bewerkingen die in een netwerk kunnen voorkomen. Ten eerste nemen de frames een suboptimaal pad naar hun bestemming, maar komen ze wel aan. In dit geval kan het netwerk een hoog bandbreedtegebruik ervaren op links die dat verkeersniveau niet zouden moeten hebben. Ten tweede vallen sommige frames weg. Deze problemen kunnen worden geïdentificeerd aan de hand van foutentellerstatistieken en consolefoutberichten die op de switch of router verschijnen. In een Ethernet-omgeving onthult een uitgebreide of continue ping ook of frames worden weggelaten.
- Overmatige broadcasts – Besturingssystemen maken veelvuldig gebruik van uitzendingen en multicasts om netwerkdiensten en andere hosts te ontdekken. Over het algemeen zijn overmatige uitzendingen het gevolg van een van de volgende situaties: slecht geprogrammeerde of geconfigureerde applicaties, grote Layer 2-broadcastdomeinen of onderliggende netwerkproblemen, zoals STP-loops of routefladderen.
- Consoleberichten – In sommige gevallen herkent een router dat er een Layer 2-probleem is opgetreden en stuurt waarschuwingsberichten naar de console. Meestal doet een router dit wanneer hij een probleem detecteert met het interpreteren van inkomende frames (inkapselings- of framingproblemen) of wanneer keepalives worden verwacht maar niet aankomen. Het meest voorkomende consolebericht dat wijst op een Layer 2-probleem, is een bericht over het uitvallen van het lijnprotocol.
Problemen op de datalinklaag die vaak leiden tot netwerkconnectiviteit of prestatieproblemen zijn onder meer:
- Inkapselingsfouten – Een inkapselingsfout treedt op omdat de bits die door de afzender in een bepaald veld zijn geplaatst, niet zijn wat de ontvanger verwacht te zien. Deze toestand doet zich voor wanneer de inkapseling aan het ene uiteinde van een WAN-link anders is geconfigureerd dan de inkapseling aan het andere uiteinde.
- Adrestoewijzingsfouten – In topologieën, zoals point-to-multipoint, Frame Relay of broadcast Ethernet, is het essentieel dat een geschikt Layer 2-bestemmingsadres aan het frame wordt gegeven. Dit zorgt ervoor dat het op de juiste bestemming aankomt. Om dit te bereiken, moet het netwerkapparaat een Layer 3-bestemmingsadres matchen met het juiste Layer 2-adres met behulp van statische of dynamische kaarten. In een dynamische omgeving kan het in kaart brengen van Layer 2- en Layer 3-informatie mislukken omdat apparaten mogelijk specifiek zijn geconfigureerd om niet te reageren op ARP- of Inverse-ARP-verzoeken, de Layer 2- of Layer 3-informatie die in de cache is opgeslagen, fysiek kan zijn gewijzigd, of ongeldige ARP-antwoorden worden ontvangen vanwege een verkeerde configuratie of een beveiligingsaanval.
- Framingfouten – Frames werken meestal in groepen van 8-bits bytes. Een framefout treedt op wanneer een frame niet eindigt op een 8-bits bytegrens. Wanneer dit gebeurt, kan de ontvanger problemen hebben om te bepalen waar een frame eindigt en een ander frame begint. Te veel ongeldige frames kunnen voorkomen dat geldige keepalives worden uitgewisseld. Framingfouten kunnen worden veroorzaakt door een seriële lijn met ruis, een onjuist ontworpen kabel (te lang of niet goed afgeschermd) of een onjuist geconfigureerde lijnklok van de Channel Service Unit (CSU).
- STP-storingen of -lussen – Het doel van het Spanning Tree Protocol (STP) is om een redundante fysieke topologie om te zetten in een boomachtige topologie door redundante poorten te blokkeren. De meeste STP-problemen hebben te maken met doorstuurlussen die optreden wanneer geen poorten in een redundante topologie worden geblokkeerd en verkeer voor onbepaalde tijd in cirkels wordt doorgestuurd, overmatige overstromingen vanwege een hoge snelheid van STP-topologieveranderingen. Een topologieverandering zou een zeldzame gebeurtenis moeten zijn in een goed geconfigureerd netwerk. Wanneer een koppeling tussen twee switches omhoog of omlaag gaat, is er uiteindelijk een topologieverandering wanneer de STP-status van de poort verandert van of naar doorsturen. Wanneer een poort echter klappert (oscilleert tussen op- en neerwaartse toestanden), veroorzaakt dit herhaalde topologieveranderingen en overstromingen, of langzame STP-convergentie of herconvergentie. Dit kan worden veroorzaakt door een mismatch tussen de echte en gedocumenteerde topologie, een configuratiefout, zoals een inconsistente configuratie van STP-timers, een overbelaste switch-CPU tijdens convergentie of een softwaredefect.
9.2.2.3. Problemen met de netwerklaag oplossen
Netwerklaagproblemen omvatten elk probleem waarbij een Layer 3-protocol betrokken is, zowel gerouteerde protocollen (zoals IPv4 of IPv6) als routeringsprotocollen (zoals EIGRP, OSPF, enz.).
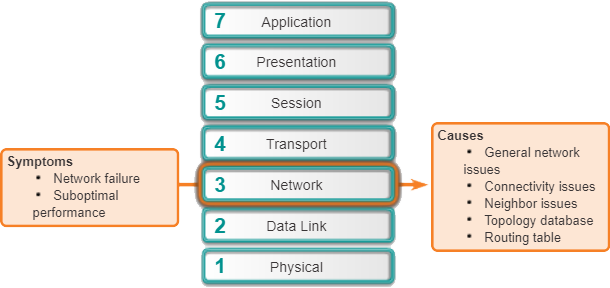
Veelvoorkomende symptomen van netwerkproblemen op de netwerklaag zijn:
- Netwerkfout – Netwerkfout is wanneer het netwerk bijna of volledig niet-functioneel is, wat gevolgen heeft voor alle gebruikers en applicaties op het netwerk. Deze storingen worden meestal snel opgemerkt door gebruikers en netwerkbeheerders en zijn uiteraard cruciaal voor de productiviteit van een bedrijf.
- Suboptimale prestaties – Problemen met netwerkoptimalisatie hebben meestal betrekking op een subset van gebruikers, applicaties, bestemmingen of een bepaald type verkeer. Optimalisatieproblemen kunnen moeilijk te detecteren en nog moeilijker te isoleren en te diagnosticeren zijn. Dit komt omdat ze meestal meerdere lagen omvatten, of zelfs de hostcomputer zelf. Het kan enige tijd duren om vast te stellen dat het probleem een netwerklaagprobleem is.
In de meeste netwerken worden statische routes gebruikt in combinatie met dynamische routeringsprotocollen. Onjuiste configuratie van statische routes kan leiden tot minder dan optimale routering. In sommige gevallen kunnen onjuist geconfigureerde statische routes routeringslussen creëren die delen van het netwerk onbereikbaar maken.
Het oplossen van problemen met dynamische routeringsprotocollen vereist een grondig begrip van hoe het specifieke routeringsprotocol functioneert. Sommige problemen zijn gemeenschappelijk voor alle routeringsprotocollen, terwijl andere problemen specifiek zijn voor het individuele routeringsprotocol.
Er is niet één sjabloon voor het oplossen van Layer 3-problemen. Routeringsproblemen worden opgelost met een methodisch proces, waarbij een reeks opdrachten wordt gebruikt om het probleem te isoleren en te diagnosticeren.
Hier zijn enkele gebieden om te onderzoeken bij het diagnosticeren van een mogelijk probleem met routeringsprotocollen:
- Algemene netwerkproblemen – Vaak kan een verandering in de topologie, zoals een downlink, effecten hebben op andere delen van het netwerk die op dat moment misschien niet duidelijk zijn. Dit kan het aanleggen van nieuwe routes zijn, statisch of dynamisch, of het verwijderen van andere routes. Bepaal of er recentelijk iets in het netwerk is veranderd en of er momenteel iemand aan de netwerkinfrastructuur werkt.
- Verbindingsproblemen – Controleer op apparatuur- en verbindingsproblemen, inclusief stroomproblemen zoals stroomuitval en omgevingsproblemen (bijvoorbeeld oververhitting). Controleer ook op Layer 1-problemen, zoals bekabelingsproblemen, slechte poorten en ISP-problemen.
- Problemen met buren – Als het routeringsprotocol een nabijheid tot een buurman tot stand brengt, controleer dan of er problemen zijn met de routers die naburige aangrenzende gebieden vormen.
- Topologiedatabase – Als het routeringsprotocol een topologietabel of database gebruikt, controleert u de tabel op onverwachte dingen, zoals ontbrekende of onverwachte vermeldingen.
- Routeringstabel – Controleer de routeringstabel op onverwachte dingen, zoals ontbrekende routes of onverwachte routes. Gebruik debug-opdrachten om routeringsupdates en routeringstabelonderhoud te bekijken.
9.2.2.4. Problemen met de transportlaag ACL’s oplossen
Netwerkproblemen kunnen ontstaan door transportlaagproblemen op de router, met name aan de rand van het netwerk waar het verkeer wordt onderzocht en aangepast. Twee van de meest geïmplementeerde transportlaagtechnologieën zijn toegangscontrolelijsten (ACL’s) en Network Address Translation (NAT).
De meest voorkomende problemen met ACL’s worden veroorzaakt door een onjuiste configuratie. Problemen met ACL’s kunnen ertoe leiden dat anders werkende systemen niet meer werken. Er zijn verschillende gebieden waar misconfiguraties vaak voorkomen:
- Selectie van verkeersstroom – De meest voorkomende verkeerde configuratie van de router is het toepassen van de ACL op onjuist verkeer. Verkeer wordt bepaald door zowel de routerinterface waar het verkeer doorheen reist als de richting waarin dit verkeer zich verplaatst. Een ACL moet worden toegepast op de juiste interface en de juiste verkeersrichting moet worden geselecteerd om goed te kunnen functioneren.
- Volgorde van access control items – De items in een ACL moeten van specifiek naar algemeen zijn. Hoewel een ACL een ingang kan hebben om specifiek een bepaalde verkeersstroom toe te staan, komen pakketten nooit overeen met die ingang als ze worden geweigerd door een andere ingang eerder in de lijst. Als de router zowel ACL’s als NAT gebruikt, is de volgorde waarin elk van deze technologieën wordt toegepast op een verkeersstroom belangrijk. Inkomend verkeer wordt verwerkt door de inkomende ACL voordat het wordt verwerkt door NAT van buiten naar binnen. Uitgaand verkeer wordt verwerkt door de uitgaande ACL nadat het is verwerkt door binnen-naar-buiten NAT.
- Impliciete alles weigeren – Wanneer hoge beveiliging niet vereist is op de ACL, kan dit impliciete toegangscontrole-element de oorzaak zijn van een verkeerde ACL-configuratie.
- Adressen en IPv4 wildcardmaskers – Complexe IPv4-jokertekenmaskers bieden aanzienlijke efficiëntieverbeteringen, maar zijn meer onderhevig aan configuratiefouten. Een voorbeeld van een complex jokertekenmasker is het gebruik van het IPv4-adres 10.0.32.0 en het jokertekenmasker 0.0.32.15 om de eerste 15 hostadressen in het 10.0.0.0-netwerk of het 10.0.32.0-netwerk te selecteren.
- Selectie van transportlaagprotocol – Bij het configureren van ACL’s is het belangrijk dat alleen de juiste transportlaagprotocollen worden gespecificeerd. Veel netwerkbeheerders configureren beide wanneer ze niet zeker weten of een bepaalde verkeersstroom een TCP-poort of een UDP-poort gebruikt. Als u beide specificeert, wordt er een gat door de firewall geopend, waardoor indringers mogelijk toegang krijgen tot het netwerk. Het introduceert ook een extra element in de ACL, zodat de ACL meer tijd nodig heeft om te verwerken, waardoor er meer latentie in de netwerkcommunicatie ontstaat.
- Bron- en doelpoorten – Om het verkeer tussen twee hosts op de juiste manier te regelen, zijn symmetrische toegangscontrole-elementen voor inkomende en uitgaande ACL’s vereist. Adres- en poortinformatie voor verkeer gegenereerd door een antwoordende host is het spiegelbeeld van adres- en poortinformatie voor verkeer gegenereerd door de initiërende host.
- Gebruik van het established sleutelwoord – Het established sleutelwoord verhoogt de beveiliging die door een ACL wordt geboden. Als het trefwoord echter onjuist wordt toegepast, kunnen er onverwachte resultaten optreden.
- Ongewone protocollen – Verkeerd geconfigureerde ACL’s veroorzaken vaak problemen voor andere protocollen dan TCP en UDP. Ongebruikelijke protocollen die aan populariteit winnen, zijn VPN- en encryptieprotocollen.
Het log-sleutelwoord is een nuttige opdracht voor het bekijken van ACL-bewerkingen op ACL-items. Dit sleutelwoord instrueert de router om een item in het systeemlogboek te plaatsen wanneer aan die ingangsvoorwaarde wordt voldaan. De geregistreerde gebeurtenis bevat details van het pakket dat overeenkomt met het ACL-element. Het log-sleutelwoord is vooral handig voor het oplossen van problemen en biedt ook informatie over inbraakpogingen die worden geblokkeerd door de ACL.
9.2.2.5. Problemen met de transportlaag NAT voor IPv4 oplossen
Er zijn een aantal problemen met NAT, zoals geen interactie met services zoals DHCP en tunneling. Deze kunnen verkeerd geconfigureerde NAT binnen, NAT buiten of ACL zijn. Andere problemen zijn interoperabiliteit met andere netwerktechnologieën, met name die welke informatie bevatten of afleiden van hostnetwerkadressering in het pakket. Sommige van deze technologieën omvatten:
- BOOTP en DHCP – Beide protocollen beheren de automatische toewijzing van IPv4-adressen aan clients. Bedenk dat het eerste pakket dat een nieuwe client verzendt een DHCP-Request broadcast IPv4-pakket is. Het DHCP-Request-pakket heeft een bron-IPv4-adres van 0.0.0.0. Omdat NAT zowel een geldig bestemmings- als een bron-IPv4-adres vereist, kunnen BOOTP en DHCP problemen ondervinden bij het werken via een router met statische of dynamische NAT. Het configureren van de IPv4-helperfunctie kan dit probleem helpen oplossen.
- DNS en WINS – Omdat een router met dynamische NAT de relatie tussen binnen- en buitenadressen regelmatig verandert als tabelgegevens verlopen en opnieuw worden gemaakt, heeft een DNS- of WINS-server buiten de NAT-router geen nauwkeurige weergave van het netwerk in de router. Het configureren van de IPv4-helperfunctie kan dit probleem helpen oplossen.
- SNMP – Net als bij DNS-pakketten kan NAT de adresseringsinformatie die is opgeslagen in de gegevenslading van het pakket niet wijzigen. Hierdoor kan een SNMP-beheerstation aan de ene kant van een NAT-router mogelijk geen contact maken met SNMP-agenten aan de andere kant van de NAT-router. Het configureren van de IPv4-helperfunctie kan dit probleem helpen oplossen.
- Tunneling- en encryptieprotocollen – Encryptie- en tunnelingprotocollen vereisen vaak dat het verkeer afkomstig is van een specifieke UDP- of TCP-poort, of een protocol op de transportlaag gebruiken dat niet door NAT kan worden verwerkt. IPsec-tunnelingprotocollen en generieke routeringsinkapselingsprotocollen die door VPN-implementaties worden gebruikt, kunnen bijvoorbeeld niet door NAT worden verwerkt.
Opmerking: DHCPv6 van een IPv6-client kan door de router worden doorgestuurd met behulp van het ipv6 dhcp-relay-commando.
9.2.2.6. Problemen met de applicatielaag oplossen
De meeste applicatielaagprotocollen bieden gebruikersservices. Applicatielaagprotocollen worden doorgaans gebruikt voor netwerkbeheer, bestandsoverdracht, gedistribueerde bestandsservices, terminalemulatie en e-mail. Vaak komen er nieuwe gebruikersdiensten bij, zoals VPN’s en VoIP.
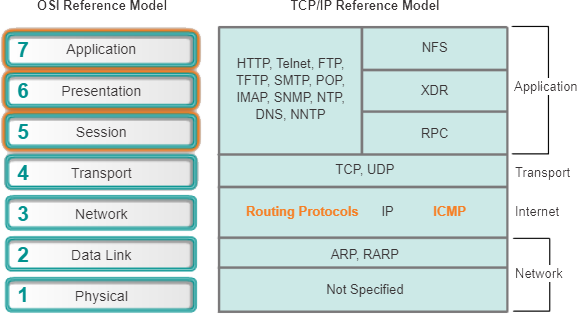
De afbeelding toont de meest bekende en geïmplementeerde TCP/IP-toepassingslaagprotocollen, waaronder:
- SSH/Telnet – Hiermee kunnen gebruikers terminalsessieverbindingen tot stand brengen met externe hosts.
- HTTP – Ondersteunt de uitwisseling van tekst, grafische afbeeldingen, geluid, video en andere multimediabestanden op internet.
- FTP – Voert interactieve bestandsoverdrachten uit tussen hosts.
- TFTP – Voert elementaire interactieve bestandsoverdrachten uit, meestal tussen hosts en netwerkapparaten.
- SMTP – Ondersteunt basisdiensten voor het bezorgen van berichten.
- POP – Maakt verbinding met e-mailservers en downloadt e-mail.
- Simple Network Management Protocol (SNMP) – Verzamelt managementinformatie van netwerkapparaten.
- DNS – wijst IP-adressen toe aan de namen die zijn toegewezen aan netwerkapparaten.
- Network File System (NFS) – Stelt computers in staat schijven op externe hosts te koppelen en deze te bedienen alsof het lokale schijven zijn. Oorspronkelijk ontwikkeld door Sun Microsystems, combineert het met twee andere applicatielaagprotocollen, externe gegevensweergave (XDR) en externe procedureaanroep (RPC), om transparante toegang tot externe netwerkbronnen mogelijk te maken.
De soorten symptomen en oorzaken zijn afhankelijk van de daadwerkelijke toepassing zelf.
Problemen met de applicatielaag voorkomen dat services worden geleverd aan applicatieprogramma’s. Een probleem op de applicatielaag kan resulteren in onbereikbare of onbruikbare bronnen wanneer de fysieke, datalink-, netwerk- en transportlagen functioneel zijn. Het is mogelijk om volledige netwerkconnectiviteit te hebben, maar de applicatie kan eenvoudigweg geen gegevens verstrekken.
Een ander type probleem op de applicatielaag doet zich voor wanneer de fysieke, datalink-, netwerk- en transportlagen functioneel zijn, maar de dataoverdracht en verzoeken om netwerkdiensten van een enkele netwerkdienst of applicatie niet voldoen aan de normale verwachtingen van een gebruiker.
Een probleem op de applicatielaag kan ertoe leiden dat gebruikers klagen dat het netwerk of de specifieke applicatie waarmee ze werken traag of langzamer is dan normaal bij het overbrengen van gegevens of het aanvragen van netwerkdiensten.
9.2.3. Problemen met IP-connectiviteit oplossen
9.2.3.1. Onderdelen voor het oplossen van problemen met end-to-end-connectiviteit
Het diagnosticeren en oplossen van problemen is een essentiële vaardigheid voor netwerkbeheerders. Er is niet één recept voor het oplossen van problemen en een bepaald probleem kan op veel verschillende manieren worden gediagnosticeerd. Door echter een gestructureerde benadering van het probleemoplossingsproces te gebruiken, kan een beheerder de tijd die nodig is om een probleem te diagnosticeren en op te lossen, verkorten.
In dit hele onderwerp wordt het volgende scenario gebruikt. De client-host-PC1 heeft geen toegang tot toepassingen op Server SRV1 of Server SRV2. De afbeelding toont de topologie van dit netwerk. PC1 gebruikt SLAAC met EUI-64 om zijn IPv6 globale unicast-adres te creëren. EUI-64 maakt de interface-ID aan met behulp van het Ethernet MAC-adres, voegt FFFE in het midden toe en draait het zevende bit om.
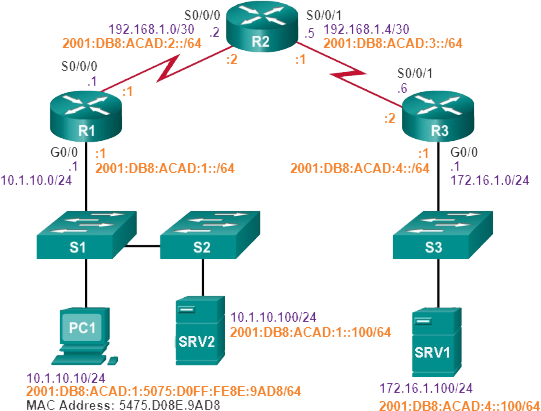
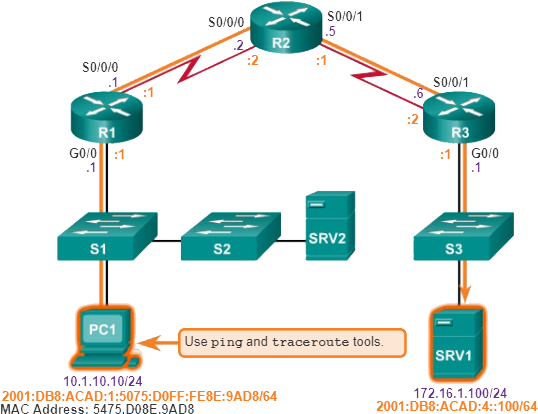
Als er geen end-to-end-connectiviteit is en de beheerder ervoor kiest om problemen op te lossen met een bottom-up-aanpak, zijn dit veelvoorkomende stappen die de beheerder kan nemen:
Stap 1. Controleer de fysieke connectiviteit op het punt waar de netwerkcommunicatie stopt. Dit is inclusief kabels en hardware. Het probleem kan te maken hebben met een defecte kabel of interface, of met verkeerd geconfigureerde of defecte hardware.
Stap 2. Controleer op duplex-mismatches.
Stap 3. Controleer datalink en netwerklaagadressering op het lokale netwerk. Dit omvat IPv4 ARP-tabellen, IPv6-buurtabellen, MAC-adrestabellen en VLAN-toewijzingen.
Stap 4. Controleer of de standaardgateway correct is.
Stap 5. Zorg ervoor dat apparaten het juiste pad van de bron naar de bestemming bepalen. Manipuleer de routeringsinformatie indien nodig.
Stap 6. Controleer of de transportlaag goed functioneert. Telnet kan ook worden gebruikt om transportlaagverbindingen vanaf de opdrachtregel te testen.
Stap 7. Controleer of er geen ACL’s zijn die het verkeer blokkeren.
Stap 8. Zorg ervoor dat de DNS-instellingen correct zijn. Er moet een DNS-server zijn die toegankelijk is.
Het resultaat van dit proces is operationele, end-to-end connectiviteit. Als alle stappen zijn uitgevoerd zonder enige oplossing, kan de netwerkbeheerder de vorige stappen herhalen of het probleem escaleren naar een senior beheerder.
9.2.3.2. End-to-end-verbindingsprobleem veroorzaakt probleemoplossing
Meestal wordt een probleemoplossing gestart door de ontdekking dat er een probleem is met de end-to-end-connectiviteit. Twee van de meest voorkomende hulpprogramma’s die worden gebruikt om een probleem met end-to-end-connectiviteit te verifiëren, zijn ping en traceroute, zoals weergegeven in het volgend voorbeeld.
Ping is waarschijnlijk het meest bekende hulpprogramma voor het testen van connectiviteit in netwerken en is altijd onderdeel geweest van Cisco IOS-software. Het verzendt verzoeken om antwoorden van een opgegeven hostadres. De ping-opdracht gebruikt een Layer 3-protocol dat deel uitmaakt van de TCP/IP-suite genaamd ICMP. Ping gebruikt het ICMP-echoverzoek en ICMP-echoantwoordpakketten. Als de host op het opgegeven adres het ICMP-echoverzoek ontvangt, reageert deze met een ICMP-echo-antwoordpakket. Ping kan worden gebruikt om end-to-end-connectiviteit voor zowel IPv4 als IPv6 te verifiëren. Afbeelding 2 toont een succesvolle ping van PC1 naar SRV1, op adres 172.16.1.100.
PC1> ping 172.16.1.100
Pinging 172.16.1.100 with 32 bytes of data:
Reply from 172.16.1.100: bytes=32 time=8ms TTL=254
Reply from 172.16.1.100: bytes=32 time=1ms TTL=254
Reply from 172.16.1.100: bytes=32 time=1ms TTL=254
Reply from 172.16.1.100: bytes=32 time=1ms TTL=254
Ping statistics for 172.16.1.100:
Packets: Sent = 4, Received = 4, Lost = 0 (0% loss),
Approximate round-trip times in milliseconds:
Minimum = 1ms, Maximum = 8ms, Average = 2msDe opdracht traceroute in het volgend voorgbeeld illustreert het pad dat de IPv4-pakketten volgen om hun bestemming te bereiken. Net als de ping-opdracht, kan de Cisco IOS-opdracht traceroute worden gebruikt voor zowel IPv4 als IPv6. De opdracht tracert wordt gebruikt met het Windows-besturingssysteem. De trace genereert een lijst met hops, IP-adressen van de router en het IP-adres van de uiteindelijke bestemming die met succes langs het pad zijn bereikt. Deze lijst bevat belangrijke informatie over verificatie en probleemoplossing. Als de gegevens de bestemming bereiken, vermeldt de trace de interface op elke router in het pad. Als de gegevens op een of andere manier mislukken, is het adres van de laatste router die op de tracering heeft gereageerd bekend. Dit adres geeft aan waar het probleem of de beveiligingsbeperkingen zich bevinden.
C:\Windows\system32> tracert 172.16.1.100
Tracing route to 172.16.1.100 over a maximum of 30 hops
1 1 ms <1 ms <1 ms 10.1.10.1
2 2 ms 2 ms 1 ms 192.168.1.2
3 2 ms 2 ms 1 ms 192.168.1.6
4 2 ms 2 ms 1 ms 172.16.1.100
Trace complete.Zoals vermeld, kunnen de hulpprogramma’s ping en traceroute worden gebruikt om end-to-end IPv6-connectiviteit te testen en te diagnosticeren door het IPv6-adres als bestemmingsadres op te geven. Bij gebruik van deze hulpprogramma’s herkent het Cisco IOS-hulpprogramma of het adres een IPv4- of IPv6-adres is en gebruikt het het juiste protocol om de connectiviteit te testen. Het volgend voorbeeld toont de ping- en traceroute-opdrachten op router R1 die worden gebruikt om de IPv6-connectiviteit te testen.
R1# ping 2001:db8:acad:4::100
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 2001:DB8:ACAD:4::100,
timeout is 2 seconds:!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max =
56/56/56 ms
R1# traceroute 2001:db8:acad:4::100
Type escape sequence to abort.
Tracing the route to 2001:DB8:ACAD:4::100
1 2001:DB8:ACAD:2::2 20 msec 20 msec 20 msec
2 2001:DB8:ACAD:3::2 44 msec 40 msec 40 msec
R1#9.2.3.3. Stap 1: Controleer de fysieke laag
Alle netwerkapparaten zijn gespecialiseerde computersystemen. Deze apparaten bestaan minimaal uit een CPU, RAM en opslagruimte, zodat het apparaat kan opstarten en het besturingssysteem en de interfaces kan uitvoeren. Dit maakt de ontvangst en verzending van netwerkverkeer mogelijk. Wanneer een netwerkbeheerder vaststelt dat er een probleem bestaat op een bepaald apparaat en dat probleem mogelijk hardwaregerelateerd is, is het de moeite waard om de werking van deze generieke componenten te controleren. De meest gebruikte Cisco IOS-commando’s voor dit doel zijn show process cpu, show memory en show interfaces. In dit onderwerp wordt het commando show interfaces besproken.
Bij het oplossen van prestatiegerelateerde problemen en als vermoed wordt dat hardware defect is, kan de opdracht show interfaces worden gebruikt om de interfaces te verifiëren waar het verkeer doorheen gaat.
R1# show interfaces GigabitEthernet 0/0
GigabitEthernet0/0 is up, line protocol is up
Hardware is CN Gigabit Ethernet, address is
d48c.b5ce.a0c0(bia d48c.b5ce.a0c0)
Internet address is 10.1.10.1/24
<output ommitted>
Input queue: 0/75/0/0 (size/max/drops/flushes); Total output drops: 0
Queueing strategy: fifo
Output queue: 0/40 (size/max)
5 minute input rate 0 bits/sec, 0 packets/sec
5 minute output rate 0 bits/sec, 0 packets/sec
85 packets input, 7711 bytes, 0 no buffer
Received 25 broadcasts (0 IP multicasts)
0 runts, 0 giants, 0 throttles
0 input errors, 0 CRC, 0 frame, 0 overrun, 0 ignored
0 watchdog, 5 multicast, 0 pause input
10112 packets output, 922864 bytes, 0 underruns
0 output errors, 0 collisions, 1 interface resets
11 unknown protocol drops
0 babbles, 0 late collision, 0 deferred
0 lost carrier, 0 no carrier, 0 pause output
0 output buffer failures, 0 output buffers swapped out
R1#De uitvoer van de opdracht show interfaces in het bovenstaand voorbeeld somt een aantal belangrijke statistieken op die gecontroleerd kunnen worden:
- Input queue drops – Dalingen in de invoerwachtrij (en de gerelateerde tellers voor genegeerde en smoorkleppen) geven aan dat er op een bepaald moment meer verkeer aan de router is geleverd dan het kon verwerken. Dit duidt niet noodzakelijk op een probleem. Dat zou normaal kunnen zijn tijdens verkeerspieken. Het kan echter een indicatie zijn dat de CPU pakketten niet op tijd kan verwerken, dus als dit aantal constant hoog is, is het de moeite waard om te proberen te zien op welke momenten deze tellers toenemen en hoe dit zich verhoudt tot het CPU-gebruik.
- Output queue drops – Dalingen in de uitvoerwachtrij geeft aan dat pakketten zijn verwijderd vanwege congestie op de interface. Het zien van outputdalingen is normaal voor elk punt waar het totale inputverkeer hoger is dan het outputverkeer. Tijdens verkeerspieken vallen pakketten weg als het verkeer sneller op de interface wordt afgeleverd dan het kan worden verzonden. Maar zelfs als dit als normaal gedrag wordt beschouwd, leidt dit tot pakketverlies en vertragingen in de wachtrij, dus toepassingen die daar gevoelig voor zijn, zoals VoIP, kunnen prestatieproblemen ondervinden. Het constant zien van outputdalingen kan een indicatie zijn dat u een geavanceerd wachtrijmechanisme moet implementeren om elke toepassing een goede QoS te bieden.
- Input errors – Invoerfouten duiden op fouten die optreden tijdens de ontvangst van het frame, zoals CRC-fouten. Hoge aantallen CRC-fouten kunnen duiden op bekabelingsproblemen, hardwareproblemen met de interface of, in een Ethernet-gebaseerd netwerk, duplex-mismatches.
- Output errors – Uitvoerfouten duiden op fouten, zoals botsingen, tijdens de verzending van een frame. In de meeste op Ethernet gebaseerde netwerken van tegenwoordig is full-duplex-transmissie de norm en is half-duplex-transmissie de uitzondering. Bij full-duplex-transmissie kunnen er geen bedrijfsbotsingen optreden; daarom duiden botsingen en vooral late botsingen vaak op duplexmismatches.
9.2.3.4. Stap 2: Controleer op niet-overeenkomende duplexen
Een andere veelvoorkomende oorzaak van interfacefouten is een niet-overeenkomende duplexmodus tussen twee uiteinden van een Ethernet-verbinding. In veel op Ethernet gebaseerde netwerken zijn point-to-point-verbindingen nu de norm en wordt het gebruik van hubs en de bijbehorende half-duplex-bewerking minder gebruikelijk. Dit betekent dat de meeste Ethernet-links tegenwoordig in full-duplex-modus werken, en hoewel botsingen als normaal werden gezien voor een Ethernet-link, geven botsingen tegenwoordig vaak aan dat duplex-onderhandeling is mislukt en dat de link niet in de juiste duplex-modus werkt.
De IEEE 802.3ab Gigabit Ethernet-standaard schrijft het gebruik van autonegotiation voor voor snelheid en duplex. Bovendien gebruiken praktisch alle Fast Ethernet NIC’s, hoewel dit niet strikt verplicht is, ook standaard autonegotiation. Het gebruik van autonegotiation voor snelheid en duplex is de huidige aanbevolen praktijk. De richtlijnen voor duplexconfiguratie zijn als volgt:
- Point-to-point Ethernet-verbindingen moeten altijd in full-duplex-modus worden uitgevoerd.
- Half-duplex is niet meer gebruikelijk en komt het meest voor als hubs worden gebruikt.
- Autonegotiation van snelheid en duplex wordt aanbevolen.
- If autonegotiation does not work, manually set the speed and duplex on both ends.
- Half-duplex on both ends performs better than a duplex mismatch.
Als duplexonderhandeling echter om de een of andere reden mislukt, kan het nodig zijn om de snelheid en duplex aan beide kanten handmatig in te stellen. Meestal betekent dit dat de duplexmodus aan beide uiteinden van de verbinding op full-duplex moet worden ingesteld. Als dit echter niet werkt, heeft half-duplex aan beide uiteinden de voorkeur boven een duplex-mismatch.
Voorbeeld van probleemoplossing
In het vorige scenario moest de netwerkbeheerder extra gebruikers aan het netwerk toevoegen. Om deze nieuwe gebruikers op te nemen heeft de netwerkbeheerder een tweede switch geïnstalleerd en op de eerste aangesloten. Kort nadat S2 aan het netwerk was toegevoegd, begonnen gebruikers op beide switches aanzienlijke prestatieproblemen te ondervinden bij het verbinden met apparaten op de andere switch, zoals weergegeven in afbeelding 2.
De netwerkbeheerder ziet een consolebericht op switch S2:
*1 maart 00:45:08.756: %CDP-4-DUPLEX_MISMATCH: duplex-mismatch ontdekt op FastEthernet0/20 (niet half-duplex), met Switch FastEthernet0/20 (half-duplex).
Met behulp van de opdracht show interfaces fa 0/20 onderzoekt de netwerkbeheerder de interface op S1 die wordt gebruikt om verbinding te maken met S2 en merkt op dat deze is ingesteld op full-duplex, zoals weergegeven in het volgend voorbeeld.
S1# show interface fa 0/20
FastEthernet0/20 is up, line protocol is up (connected)
Hardware is Fast Ethernet, address is 0cd9.96e8.8a01 (bia
0cd9.96e8.8a01)
MTU 1500 bytes, BW 10000 Kbit/sec, DLY 1000 usec,
reliability 255/255, txload 1/255, rxload 1/255
Encapsulation ARPA, loopback not set
Keepalive set (10 sec)
Full-duplex, Auto-speed, media type is 10/100BaseTX
<output omitted>De netwerkbeheerder onderzoekt nu de andere kant van de verbinding , de poort op S2. In het volgend voorbeeld is te zien dat deze kant van de verbinding is geconfigureerd voor half-duplex. De netwerkbeheerder corrigeert de instelling naar duplex auto om automatisch over de duplex te onderhandelen. Omdat de poort op S1 is ingesteld op full-duplex, gebruikt S2 ook full-duplex.
S2# show interface fa 0/20
FastEthernet0/20 is up, line protocol is up (connected)
Hardware is Fast Ethernet, address is 0cd9.96d2.4001 (bia
0cd9.96d2.4001)
MTU 1500 bytes, BW 100000 Kbit/sec, DLY 100 usec,
reliability 255/255, txload 1/255, rxload 1/255
Encapsulation ARPA, loopback not set
Keepalive set (10 sec)
Half-duplex, Auto-speed, media type is 10/100BaseTX
<output omitted>
Switch(config)# interface fa 0/20
Switch(config-if)# duplex auto
Switch(config-if)# De gebruikers melden dat er geen prestatieproblemen meer zijn.
9.2.3.5. Stap 3: Controleer de adressering van laag 2 en laag 3 lokaal Netwerk
Bij het oplossen van problemen met end-to-end-connectiviteit is het handig om de toewijzingen tussen doel-IP-adressen en Layer 2 Ethernet-adressen op afzonderlijke segmenten te verifiëren. In IPv4 wordt deze functionaliteit geleverd door ARP. In IPv6 wordt de ARP-functionaliteit vervangen door het buurdetectieproces en ICMPv6. De buurtabel slaat IPv6-adressen en hun opgeloste fysieke Ethernet-adressen (MAC) op in de cache.
IPv4 ARP-tabel
De arp Windows-opdracht toont en wijzigt vermeldingen in de ARP-cache die worden gebruikt om IPv4-adressen en hun opgeloste fysieke Ethernet-adressen (MAC-adressen) op te slaan. Zoals te zien is in afbeelding 1, geeft de opdracht arp Windows alle apparaten weer die zich momenteel in de ARP-cache bevinden. De informatie die voor elk apparaat wordt weergegeven, omvat het IPv4-adres, het fysieke (MAC) adres en het type adressering (statisch of dynamisch).
De cache kan worden gewist met behulp van de Windows-opdracht arp -d als de netwerkbeheerder de cache opnieuw wil vullen met bijgewerkte informatie.
Opmerking: de arp-opdrachten in Linux en MAC OS X hebben een vergelijkbare syntaxis.
PC1> arp -a
Interface: 10.1.10.100 --- 0xd
Internet Address Physical Address Type
10.1.10.1 d4-8c-b5-ce-a0-c0 dynamic
224.0.0.22 01-00-5e-00-00-16 static
224.0.0.252 01-00-5e-00-00-fc static
255.255.255.255 ff-ff-ff-ff-ff-ff staticIPv6 buurtabel
Zoals weergegeven in het volgend voorbeeld, geeft de netsh interface ipv6 show neighbor Windows-opdracht alle apparaten weer die zich momenteel in de buurtabel bevinden. De informatie die voor elk apparaat wordt weergegeven, omvat het IPv6-adres, het fysieke (MAC) adres en het type adressering. Door de buurtabel te onderzoeken, kan de netwerkbeheerder controleren of de bestemmings-IPv6-adressen zijn toegewezen aan de juiste Ethernet-adressen. De IPv6-link-local-adressen op alle R1-interfaces zijn handmatig geconfigureerd op FE80::1. Evenzo is R2 geconfigureerd met het link-local adres van FE80::2 op zijn interfaces en R3 is geconfigureerd met het link-local adres van FE80::3 op zijn interfaces. Onthoud dat link-local adressen alleen uniek hoeven te zijn op de link of het netwerk.
Opmerking: de buurtabel voor Linux en MAC OS X kan worden weergegeven met de opdracht ip neigh show.
PC1> netsh interface ipv6 show neighbor
Interface 13: LAB
Internet Address Physical Address Type
---------------------- ---------------- -------
fe80::9c5a:e957:a865:bde9 00-0c-29-36-fd-f7 Stale
fe80::1 d4-8c-b5-ce-a0-c0 Reachable (Router)
ff02::2 33-33-00-00-00-02 Permanent
ff02::16 33-33-00-00-00-16 Permanent
ff02::1:2 33-33-00-01-00-02 Permanent
ff02::1:3 33-33-00-01-00-03 Permanent
ff02::1:ff05:f9fb 33-33-ff-05-f9-fb Permanent
ff02::1:ffce:a0c0 33-33-ff-ce-a0-c0 Permanent
ff02::1:ff65:bde9 33-33-ff-65-bd-e9 Permanent
ff02::1:ff67:bae4 33-33-ff-67-ba-e4 PermanentHet volgend voorbeeld toont de buurtabel op de Cisco IOS-router, met behulp van de opdracht show ipv6 buren.
Opmerking: de buurstatussen voor IPv6 zijn complexer dan de ARP-tabelstatussen in IPv4. Aanvullende informatie is opgenomen in RFC 4861.
R1# show ipv6 neighbors
IPv6 Address Age Link-layer Addr State Interface
FE80::21E:7AFF:FE79:7A81 8 001e.7a79.7a81 STALE Gi0/0
2001:DB8:ACAD:1:5075:D0FF:FE8E:9AD8 0 5475.d08e.9ad8 REACH Gi0/0Switch MAC-adrestabel
Een switch stuurt een frame alleen door naar de poort waarop de bestemming is aangesloten. Hiervoor raadpleegt de switch zijn MAC-adrestabel. De MAC-adrestabel vermeldt het MAC-adres dat op elke poort is aangesloten. Gebruik de opdracht show mac address-table om de MAC-adrestabel op de switch weer te geven. Een voorbeeld van de lokale switch van PC1 wordt getoond in het volgend voorbeeld. Onthoud dat de MAC-adrestabel van een switch alleen Layer 2-informatie bevat, inclusief het Ethernet MAC-adres en het poortnummer. IP-adresgegevens zijn niet inbegrepen.
S1# show mac address-table
Mac Address Table
-------------------------------------------
Vlan Mac Address Type Ports
All 0100.0ccc.cccc STATIC CPU
All 0100.0ccc.cccd STATIC CPU
10 d48c.b5ce.a0c0 DYNAMIC Fa0/4
10 000f.34f9.9201 DYNAMIC Fa0/5
10 5475.d08e.9ad8 DYNAMIC Fa0/13
Total Mac Addresses for this criterion: 5VLAN-toewijzing
Een ander probleem waarmee u rekening moet houden bij het oplossen van problemen met end-to-end-connectiviteit, is VLAN-toewijzing. In het geschakelde netwerk behoort elke poort in een switch tot een VLAN. Elk VLAN wordt beschouwd als een afzonderlijk logisch netwerk en pakketten die bestemd zijn voor stations die niet tot het VLAN behoren, moeten worden doorgestuurd via een apparaat dat routering ondersteunt. Als een host in één VLAN een broadcast Ethernet-frame verzendt, zoals een arp-verzoek, ontvangen alle hosts in hetzelfde VLAN het frame; hosts in andere VLAN’s niet. Zelfs als twee hosts zich in hetzelfde IP-netwerk bevinden, kunnen ze niet communiceren als ze zijn verbonden met poorten die zijn toegewezen aan twee afzonderlijke VLAN’s. Bovendien, als het VLAN waartoe de poort behoort, wordt verwijderd, wordt de poort inactief. Alle hosts die zijn aangesloten op poorten die behoren tot het VLAN dat is verwijderd, kunnen niet communiceren met de rest van het netwerk. Commando’s zoals show vlan kunnen worden gebruikt om vlan-toewijzingen op een switch te valideren.
Voorbeeld van probleemoplossing
Raadpleeg de topologie in het volgend afbeelding. Om het draadbeheer in de bedradingskast te verbeteren, werden de kabels die op S1 aangesloten waren, gereorganiseerd. Vrijwel direct daarna begonnen gebruikers de supportdesk te bellen met de mededeling dat ze apparaten buiten hun eigen netwerk niet meer konden bereiken. Een onderzoek van de ARP-tabel van PC1 met behulp van de arp Windows-opdracht toont aan dat de ARP-tabel niet langer een item voor de standaardgateway 10.1.10.1 bevat, zoals weergegeven in het volgend voorbeeld. Er waren geen configuratiewijzigingen op de router, dus S1 is de focus van het oplossen van problemen.
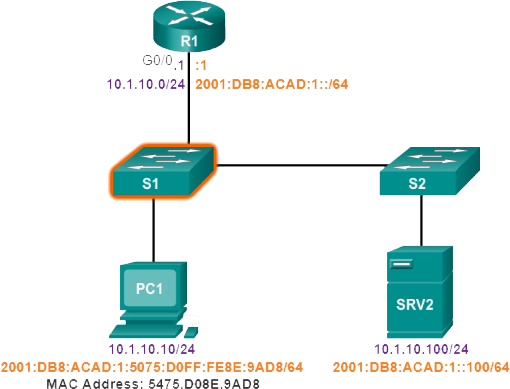
PC1> arp -a
Interface: 10.1.10.100 --- 0xd
Internet Address Physical Address Type
224.0.0.22 01-00-5e-00-00-16 static
224.0.0.252 01-00-5e-00-00-fc static
255.255.255.255 ff-ff-ff-ff-ff-ff staticDe MAC-adrestabel voor S1, zoals weergegeven in het volgend voorbeeld, laat zien dat het MAC-adres voor R1 zich op een ander VLAN bevindt dan de rest van de 10.1.10.0/24-apparaten, inclusief PC1. Tijdens de herbekabeling werd de patchkabel van R1 verplaatst van Fa 0/4 op VLAN 10 naar Fa 0/1 op VLAN 1.
S1# show mac address-table
Mac Address Table
-------------------------------------------
Vlan Mac Address Type Ports
All 0100.0ccc.cccc STATIC CPU
All 0100.0ccc.cccd STATIC CPU
1 d48c.b5ce.a0c0 DYNAMIC Fa0/1
10 000f.34f9.9201 DYNAMIC Fa0/5
10 5475.d08e.9ad8 DYNAMIC Fa0/13
Total Mac Addresses for this criterion: 5Nadat de netwerkbeheerder de Fa 0/1-poort van S1 had geconfigureerd om op VLAN 10 te zijn, zoals weergegeven in onderstaand voorbeeld, het probleem is opgelost.
S1(config)# interface fa 0/1
S1(config-if)# switchport mode access
S1(config-if)# switchport access vlan 10
S1(config-if)#Zoals weergegeven in het volgend voorbeeld, toont de MAC-adrestabel nu VLAN 10 voor het MAC-adres van R1 op poort Fa 0/1.
S1# show mac address-table
Mac Address Table
-------------------------------------------
Vlan Mac Address Type Ports
All 0100.0ccc.cccc STATIC CPU
All 0100.0ccc.cccd STATIC CPU
1 d48c.b5ce.a0c0 DYNAMIC Fa0/1
10 000f.34f9.9201 DYNAMIC Fa0/5
10 5475.d08e.9ad8 DYNAMIC Fa0/13
Total Mac Addresses for this criterion: 59.2.3.6. Stap 4: Controleer de standaardgateway
Als er geen gedetailleerde route op de router is of als de host is geconfigureerd met de verkeerde standaardgateway, werkt de communicatie tussen twee eindpunten in verschillende netwerken niet. De onderstaande afbeelding illustreert dat PC1 R1 als standaardgateway gebruikt. Evenzo gebruikt R1 R2 als de standaardgateway of als laatste redmiddel.
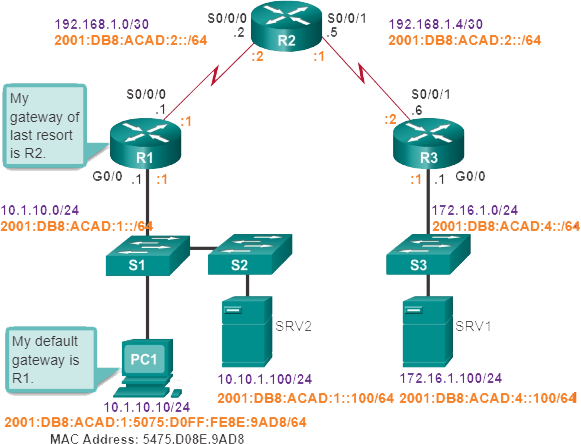
Als een host toegang nodig heeft tot bronnen buiten het lokale netwerk, moet de standaardgateway worden geconfigureerd. De standaardgateway is de eerste router op het pad naar bestemmingen buiten het lokale netwerk.
Probleemoplossing Voorbeeld 1
Afbeelding 2 toont de Cisco IOS-opdracht show ip route en de Windows-opdracht route print om de aanwezigheid van de IPv4-standaardgateway te verifiëren.
R1# show ip route
Gateway of last resort is 192.168.1.2 to network 0.0.0.0
S* 0.0.0.0/0 [1/0] via 192.168.1.2C:\Windows\system32> route print
Network Destination Netmask Gateway Interface Metric
0.0.0.0 0.0.0.0 10.1.10.2 10.1.10.100 11In dit voorbeeld heeft de R1-router de juiste standaardgateway, namelijk het IPv4-adres van de R2-router. PC1 heeft echter de verkeerde standaardgateway. PC1 moet de standaardgateway van R1-router 10.1.10.1 hebben. Dit moet handmatig worden geconfigureerd als de IPv4-adresseringsinformatie handmatig is geconfigureerd op pc1. Als de IPv4-adresseringsinformatie automatisch is verkregen van een DHCPv4-server, moet de configuratie op de DHCP-server worden onderzocht. Een configuratieprobleem op een DHCP-server wordt meestal door meerdere clients gezien.
Probleemoplossing Voorbeeld 2
In IPv6 kan de standaardgateway handmatig worden geconfigureerd of met behulp van stateless autoconfiguration (SLAAC) of DHCPv6. Met SLAAC wordt de standaardgateway door de router geadverteerd aan hosts met behulp van ICMPv6 Router Advertisement (RA)-berichten. De standaardgateway in het RA-bericht is het link-local IPv6-adres van een routerinterface. Als de standaardgateway handmatig op de host wordt geconfigureerd, wat zeer onwaarschijnlijk is, kan de standaardgateway worden ingesteld op het globale IPv6-adres of op het link-local IPv6-adres.
Zoals weergegeven in het volgend voorbeeld, geeft de Cisco IOS-opdracht show ipv6-route de IPv6-standaardroute op R1 weer en wordt de Windows-opdracht ipconfig gebruikt om de aanwezigheid van de IPv6-standaardgateway te verifiëren.
R1# show ipv6 route
S ::/0 [1/0]
via 2001:DB8:ACAD:2::2C:\Windows\system32> ipconfig
Windows IP Configuration
Connection-specific DNS Suffix . :
Link-local IPv6 Address . . . . . :
fe80::5075:d0ff:fe8e:9ad8%13
IPv4 Address. . . . . . . . . . . : 10.1.1.100
Subnet Mask . . . . . . . . . . . : 255.255.255.0
Default Gateway . . . . . . . . . : 10.1.10.1R1 heeft een standaardroute via router R2, maar merk op dat de opdracht ipconfig de afwezigheid van een IPv6 globaal unicast-adres en een standaard IPv6-gateway onthult. PC1 is ingeschakeld voor IPv6 omdat het een IPv6 link-local adres heeft. Het link-local adres wordt automatisch aangemaakt door het apparaat. De netwerkbeheerder controleert de netwerkdocumentatie en bevestigt dat hosts op dit LAN hun IPv6-adresinformatie van de router zouden moeten ontvangen met behulp van SLAAC.
Opmerking: in dit voorbeeld zouden andere apparaten op hetzelfde LAN die SLAAC gebruiken hetzelfde probleem ondervinden bij het ontvangen van IPv6-adresinformatie.
Met behulp van de opdracht show ipv6 interface GigabitEthernet 0/0 in het volgend voorbeeld, kan worden gezien dat hoewel de interface een IPv6-adres heeft, deze geen lid is van de All-IPv6-Routers multicast-groep FF02::2. Dit betekent dat de router geen ICMPv6 RA’s op deze interface verzendt.
R1# show ipv6 interface GigabitEthernet 0/0
GigabitEthernet0/0 is up, line protocol is up
IPv6 is enabled, link-local address is FE80::1
No Virtual link-local address(es):
Global unicast address(es):
2001:DB8:ACAD:1::1, subnet is 2001:DB8:ACAD:1::/64
Joined group address(es):
FF02::1
FF02::1:FF00:1In onderstaand voorbeeld is R1 ingeschakeld als een IPv6-router met behulp van de ipv6 unicast-routing-opdracht. De opdracht show ipv6 interface GigabitEthernet 0/0 onthult nu dat R1 lid is van FF02::2, de All-IPv6-Routers multicast-groep.
R1(config)# ipv6 unicast-routing
R1(config)# end
R1# show ipv6 interface GigabitEthernet 0/0
GigabitEthernet0/0 is up, line protocol is up
IPv6 is enabled, link-local address is FE80::1
No Virtual link-local address(es):
Global unicast address(es):
2001:DB8:ACAD:1::1, subnet is 2001:DB8:ACAD:1::/64
Joined group address(es):
FF02::1
FF02::2
FF02::1:FF00:1Gebruik de opdracht ipconfig op de Microsoft Windows-pc of de opdracht ifconfig op Linux en Mac OS X om te controleren of PC1 de standaardgateway heeft ingesteld. In het volgend voorbeeld heeft PC1 een globaal IPv6-unicast-adres en een standaard IPv6-gateway. De standaard gateway is ingesteld op het link-local adres van router R1, FE80::1.
PC1> ipconfig
Windows IP Configuration
Connection-specific DNS Suffix :
IPv6 Address. . . . . . . . . :
2001:db8:acad:1:5075:d0ff:fe8e:9ad8
Link-local IPv6 Address . . . : fe80::5075:d0ff:fe8e:9ad8%13
IPv4 Address. . . . . . . . . : 10.1.1.100
Subnet Mask . . . . . . . . . : 255.255.255.0
Default Gateway . . . . . . . : fe80::1
10.1.10.19.2.3.7. Stap 5: Controleer het juiste pad
Problemen met de netwerklaag oplossen
Bij het oplossen van problemen is het vaak nodig om het pad naar het doelnetwerk te verifiëren. Onderstaande afbeelding toont de referentietopologie die het beoogde pad voor pakketten van PC1 naar SRV1 aangeeft.
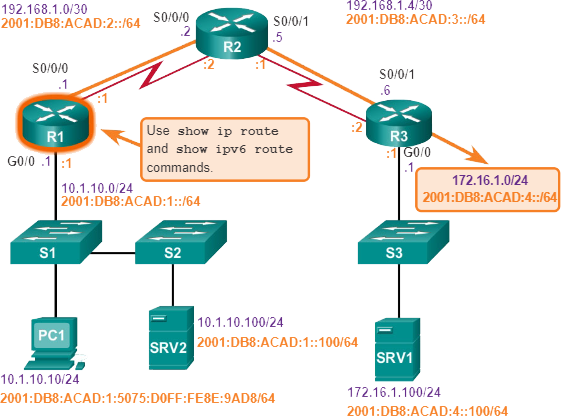
In Afbeelding 2 wordt de opdracht show ip route gebruikt om de IPv4-routeringstabel te onderzoeken.
R1# show ip route
Codes: L - local, C - connected, S - static, R - RIP, M - mobile
B - BGP, D - EIGRP, EX - EIGRP external, O - OSPF
IA - OSPF inter area, N1 - OSPF NSSA external type 1
N2 - OSPF NSSA external type 2, E1 - OSPF external type 1
E2 - OSPF external type 2 i - IS-IS, su - IS-IS summary
L1 - IS-IS level-1, L2 - IS-IS level-2
ia - IS-IS inter area, * - candidate default
U - per-user static route, o - ODR
P - periodic downloaded static route, H - NHRP l - LISP
+ - replicated route, % - next hop override
Gateway of last resort is 192.168.1.2 to network 0.0.0.0
S* 0.0.0.0/0 [1/0] via 192.168.1.2
10.0.0.0/8 is variably subnetted, 2 subnets, 2 masks
C 10.1.10.0/24 is directly connected, GigabitEthernet0/0
L 10.1.10.1/32 is directly connected, GigabitEthernet0/0
172.16.0.0/24 is subnetted, 1 subnets
D 172.16.1.0 [90/41024256] via 192.168.1.2, 05:32:46, Serial0/0/0
192.168.1.0/24 is variably subnetted, 3 subnets, 2 masks
C 192.168.1.0/30 is directly connected, Serial0/0/0
L 192.168.1.1/32 is directly connected, Serial0/0/0
D 192.168.1.4/30 [90/41024000] via 192.168.1.2, 05:32:46, Serial0/0/0
R1#De IPv4- en IPv6-routeringstabellen kunnen op de volgende manieren worden ingevuld:
- Direct verbonden netwerken
- Lokale host of lokale routes
- Statische routes
- Dynamische routes
- Standaardroutes
Het proces van het doorsturen van IPv4- en IPv6-pakketten is gebaseerd op de langste bitovereenkomst of langste prefixovereenkomst. Het routeringstabelproces zal proberen het pakket door te sturen met behulp van een item in de routeringstabel met het grootste aantal uiterst links overeenkomende bits. Het aantal overeenkomende bits wordt aangegeven door de prefixlengte van de route.
Het volgend voorbeeld toont een soortgelijk scenario met IPv6. Om te controleren of het huidige IPv6-pad overeenkomt met het gewenste pad om bestemmingen te bereiken, gebruikt u de opdracht show ipv6 route op een router om de routeringstabel te bekijken. Na bestudering van de IPv6-routeringstabel heeft R1 een pad naar 2001:DB8:ACAD:4::/64 via R2 op FE80::2.
R1# show ipv6 route
IPv6 Routing Table - default - 7 entries
Codes: C - Connected, L - Local, S - Static
U - Per-user Static route, B - BGP, R - RIP
I1 - ISIS L1, I2 - ISIS L2, A - ISIS interarea
IS - ISIS summary, D - EIGRP, EX - EIGRP external
ND - ND Default, NDp - ND Prefix, DCE - Destination
NDr - Redirect, O - OSPF Intra, OI - OSPF Inter
OE1 - OSPF ext 1, OE2 - OSPF ext 2, ON1 - OSPF NSSA ext 1
ON2 - OSPF NSSA ext 2
S ::/0 [1/0]
via 2001:DB8:ACAD:2::2
C 2001:DB8:ACAD:1::/64 [0/0]
via GigabitEthernet0/0, directly connected
L 2001:DB8:ACAD:1::1/128 [0/0]
via GigabitEthernet0/0, receive
C 2001:DB8:ACAD:2::/64 [0/0]
via Serial0/0/0, directly connected
L 2001:DB8:ACAD:2::1/128 [0/0]
via Serial0/0/0, receive
D 2001:DB8:ACAD:3::/64 [90/41024000]
via FE80::2, Serial0/0/0
D 2001:DB8:ACAD:4::/64 [90/41024256]
via FE80::2, Serial0/0/0
L FF00::/8 [0/0]
via Null0, receive
R1#De volgende lijst, samen met volgende afbeelding, beschrijft het proces voor zowel de IPv4- als IPv6-routeringstabellen. Als het bestemmingsadres in een pakket:
- Komt niet overeen met een item in de routeringstabel, dan wordt de standaardroute gebruikt. Als er geen standaardroute is geconfigureerd, wordt het pakket weggegooid.
- Komt overeen met een enkele vermelding in de routeringstabel, dan wordt het pakket doorgestuurd via de interface die in deze route is gedefinieerd.
- Komt overeen met meer dan één item in de routeringstabel en de routeringsitems hebben dezelfde prefixlengte, dan kunnen de pakketten voor deze bestemming worden verdeeld over de routes die zijn gedefinieerd in de routeringstabel.
- Komt overeen met meer dan één item in de routeringstabel en de routeringsitems hebben verschillende prefixlengtes, dan worden de pakketten voor deze bestemming doorgestuurd uit de interface die is gekoppeld aan de route met de langere prefixovereenkomst.

Voorbeeld van probleemoplossing
Apparaten kunnen geen verbinding maken met de server SRV1 op 172.16.1.100. Met behulp van de opdracht show ip route moet de beheerder controleren of er een routeringsitem bestaat naar netwerk 172.16.1.0/24. Als de routeringstabel geen specifieke route naar het netwerk van SRV1 heeft, moet de netwerkbeheerder controleren op het bestaan van een standaard- of samenvattingsroute-invoer in de richting van het 172.16.1.0/24-netwerk. Als er geen is, ligt het probleem mogelijk bij de routering en moet de beheerder controleren of het netwerk is opgenomen in de configuratie van het dynamische routeringsprotocol, of een statische route toevoegen.
9.2.3.8. Stap 6: Controleer de transportlaag
Problemen met de transportlaag oplossen
Als de netwerklaag lijkt te functioneren zoals verwacht, maar gebruikers nog steeds geen toegang hebben tot bronnen, moet de netwerkbeheerder beginnen met het oplossen van problemen met de bovenste lagen. Twee van de meest voorkomende problemen die van invloed zijn op de connectiviteit van de transportlaag, zijn ACL-configuraties en NAT-configuraties. Een veelgebruikt hulpmiddel voor het testen van de functionaliteit van de transportlaag is het hulpprogramma Telnet.
Let op: Hoewel Telnet kan worden gebruikt om de transportlaag te testen, moet om veiligheidsredenen SSH worden gebruikt om apparaten op afstand te beheren en te configureren.
Een netwerkbeheerder lost een probleem op waarbij iemand geen e-mail kan verzenden via een bepaalde SMTP-server. De beheerder pingt de server en deze reageert. Dit betekent dat de netwerklaag, en alle lagen onder de netwerklaag, tussen de gebruiker en de server operationeel is. De beheerder weet dat het probleem bij laag 4 of hoger ligt en moet beginnen met het oplossen van problemen met die lagen.
Hoewel de telnet-servertoepassing op zijn eigen bekende poortnummer 23 draait en Telnet-clients standaard verbinding maken met deze poort, kan op de client een ander poortnummer worden opgegeven om verbinding te maken met elke TCP-poort die moet worden getest. Dit geeft aan of de verbinding wordt geaccepteerd (zoals aangegeven door het woord “Open” in de uitvoer), wordt geweigerd of een time-out optreedt. Uit elk van die reacties kunnen verdere conclusies worden getrokken met betrekking tot de connectiviteit. Bepaalde toepassingen kunnen, als ze een op ASCII gebaseerd sessieprotocol gebruiken, zelfs een toepassingsbanner weergeven. Het kan mogelijk zijn om enkele reacties van de server te activeren door bepaalde trefwoorden in te typen, zoals met SMTP, FTP en HTTP.
In het vorige scenario is de beheerder Telnets van PC1 naar het serverhoofdkwartier, gebruikmakend van IPv6, en is de Telnet-sessie succesvol, zoals weergegeven in het volgend voorbeeld.
PC1> telnet 2001:DB8:172:16::100
HQ#In het volgend voorbeeld probeert de beheerder Telnet naar dezelfde server te sturen, via poort 80. De uitvoer verifieert of de transportlaag met succes verbinding maakt van PC1 naar HQ. De server accepteert echter geen verbindingen op poort 80.
PC1> telnet 2001:DB8:172:16::100 80
HTTP/1.1 400 Bad Request
Date: Wed, 26 Sep 2012 07:27:10 GMT
Server: cisco-IOS
Accept-Ranges: none
400 Bad Request
Connection to host lost.Het voorbeeld in afbeelding 3 toont een succesvolle Telnet-verbinding van R1 naar R3, via IPv6.
R1# telnet 2001:db8:acad:3::2
Trying 2001:DB8:ACAD:3::2 ... Open
User Access Verification
Password:
R3>Afbeelding 4 is een vergelijkbare Telnet-poging die poort 80 gebruikt. Nogmaals, de uitvoer verifieert een geslaagde transportlaagverbinding, maar R3 weigert de verbinding via poort 80.
R1# telnet 2001:db8:acad:3::2 80
Trying 2001:DB8:ACAD:3::2, 80 ...
% Connection refused by remote host
R1#9.2.3.9. Stap 7: ACL’s verifiëren
Op routers kunnen ACL’s zijn geconfigureerd die verhinderen dat protocollen de interface in inkomende of uitgaande richting passeren.
Gebruik de opdracht show ip access-lists om de inhoud van alle IPv4 ACL’s weer te geven en de opdracht show ipv6 access-list om de inhoud weer te geven van alle IPv6 ACL’s die op een router zijn geconfigureerd. De specifieke ACL kan worden weergegeven door de ACL-naam of het nummer in te voeren als een optie voor deze opdracht; u kunt een specifieke ACL weergeven. De opdrachten show ip interfaces en show ipv6 interfaces geven IPv4- en IPv6-interface-informatie weer die aangeeft of er IP-ACL’s zijn ingesteld op de interface.
Voorbeeld van probleemoplossing
Om spoofing-aanvallen te voorkomen, heeft de netwerkbeheerder besloten om een ACL te implementeren die voorkomt dat apparaten met een bronnetwerkadres van 172.16.1.0/24 de inkomende S0/0/1-interface op R3 binnenkomen, zoals weergegeven in de onderstaande afbeelding. Al het andere IP-verkeer moet toegestaan.
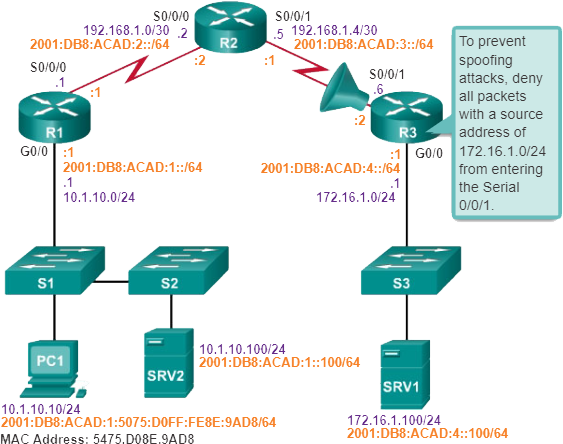
Kort na de implementatie van de ACL konden gebruikers op het 10.1.10.0/24-netwerk echter geen verbinding maken met apparaten op het 172.16.1.0/24-netwerk, inclusief SRV1. De opdracht show ip access-lists laat zien dat de ACL correct is geconfigureerd, zoals weergegeven in het volgend voorbeeld. De opdracht show ip interfaces serial 0/0/1 laat echter zien dat de ACL nooit is toegepast op de inkomende interface op s0/0/ 1. Nader onderzoek onthult dat de ACL per ongeluk is toegepast op de G0/0-interface, waardoor al het uitgaande verkeer van het 172.16.1.0/24-netwerk werd geblokkeerd.
R3# show ip access-lists
Extended IP access list 100
deny ip 172.16.1.0 0.0.0.255 any (3 match(es))
permit ip any any
R3# show ip interface Serial 0/0/1 | include access list
Outgoing access list is not set
Inbound access list is not set
R3# show ip interface gigabitethernet 0/0 | include access list
Outgoing access list is not set
Inbound access list is 100Nadat de IPv4-ACL correct op de s0/0/1 inkomende interface is geplaatst, zoals weergegeven in het volgend voorbeeld, kunnen apparaten verbinding maken met de server.
R3(config)# interface gigabitethernet 0/0
R3(config-if)# no ip access-group 100 in
R3(config-if)# interface serial 0/0/1
R3(config-if)# ip access-group 100 in9.2.3.10. Stap 8: DNS verifiëren
Het DNS-protocol stuurt de DNS aan, een gedistribueerde database waarmee u hostnamen aan IP-adressen kunt toewijzen. Wanneer u DNS op het apparaat configureert, kunt u de hostnaam voor het IP-adres vervangen door alle IP-opdrachten, zoals ping of telnet.
Gebruik de opdracht show running-config om de DNS-configuratie-informatie op de switch of router weer te geven. Als er geen DNS-server is geïnstalleerd, is het mogelijk om namen voor IP-toewijzingen rechtstreeks in de switch- of routerconfiguratie in te voeren. Gebruik de opdracht ip host om de naam in te voeren voor de IPv4-toewijzing aan de switch of router. De opdracht ipv6 host wordt gebruikt voor dezelfde toewijzingen met IPv6. Deze opdrachten worden gedemonstreerd in het volgend voorbeeld. Omdat IPv6-netwerknummers lang en moeilijk te onthouden zijn, is DNS nog belangrijker voor IPv6 dan voor IPv4.
R1(config)# ip host ipv4-server 172.16.1.100
R1(config)# exit
R1# ping ipv4-server
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 172.16.1.100,
timeout is 2 seconds:
!!!!!
Success rate is 100 percent (5/5),
round-trip min/avg/max = 52/56/64 ms
R1#
R1# conf t
R1(config)# ipv6 host ipv6-server 2001:db8:acad:4::100
R1(config)# exit
R1# ping ipv6-server
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 2001:DB8:ACAD:4::100,
timeout is 2 seconds:
!!!!!
Success rate is 100 percent (5/5),
round-trip min/avg/max = 52/54/56 ms
R1#Gebruik de opdracht nslookup om de toewijzingsinformatie van naam naar IP-adres op de Windows-pc weer te geven.
Voorbeeld van probleemoplossing
De uitvoer in het volgend voorbeeld geeft aan dat de client de DNS-server niet kon bereiken of dat de DNS-service op 10.1.1.1 niet actief was. Op dit punt moet de probleemoplossing zich richten op communicatie met de DNS-server, of controleren of de DNS-server correct werkt.
PC1> nslookup Server
*** Request to 10.1.1.1 timed-outGebruik de opdracht nslookup om de DNS-configuratie-informatie op een Microsoft Windows-pc weer te geven. Er moet DNS zijn geconfigureerd voor IPv4, IPv6 of beide. DNS kan tegelijkertijd IPv4- en IPv6-adressen leveren, ongeacht het protocol dat wordt gebruikt om toegang te krijgen tot de DNS-server.
Omdat domeinnamen en DNS een essentieel onderdeel zijn van toegang tot servers op het netwerk, denkt de gebruiker vaak dat het “netwerk niet werkt” terwijl het probleem feitelijk bij de DNS-server ligt.
9.3. Samenvatting
Om netwerkbeheerders in staat te stellen een netwerk te bewaken en problemen op te lossen, moeten ze een volledige set nauwkeurige en actuele netwerkdocumentatie hebben, inclusief configuratiebestanden, fysieke en logische topologiediagrammen en een basisprestatieniveau.
De drie belangrijkste fasen voor het oplossen van problemen zijn het verzamelen van symptomen, het isoleren van het probleem en het oplossen van het probleem. Soms is het nodig om tijdelijk een tijdelijke oplossing voor het probleem te implementeren. Als de beoogde corrigerende actie het probleem niet oplost, moet de wijziging worden verwijderd. In alle processtappen dient de netwerkbeheerder het proces te documenteren. Voor elke fase moet een beleid voor het oplossen van problemen worden vastgesteld, inclusief procedures voor wijzigingsbeheer. Nadat het probleem is opgelost, is het belangrijk om dit te communiceren aan de gebruikers, iedereen die betrokken is bij het probleemoplossingsproces en aan andere IT-teamleden.
Het OSI-model of het TCP/IP-model kan worden toegepast op een netwerkprobleem. Een netwerkbeheerder kan de bottom-up methode, de top-down methode of de verdeel-en-heers methode gebruiken. Minder gestructureerde methoden zijn shoot-from-the-hip, spot-the-verschillen en move-the-problem.
Veelgebruikte softwaretools die kunnen helpen bij het oplossen van problemen zijn onder meer netwerkbeheersysteemtools, kennisbanken, baselinetools, hostgebaseerde protocolanalysatoren en Cisco IOS EPC. Tools voor het oplossen van hardwareproblemen omvatten een NAM, digitale multimeters, kabeltesters, kabelanalysatoren en draagbare netwerkanalysatoren. Cisco IOS-loggegevens kunnen ook worden gebruikt om mogelijke problemen te identificeren.
Er zijn kenmerkende fysieke laag, datalinklaag, netwerklaag, transportlaag en applicatielaag symptomen en problemen waarvan de netwerkbeheerder op de hoogte moet zijn. De beheerder moet mogelijk bijzondere aandacht besteden aan fysieke connectiviteit, standaardgateways, MAC-adrestabellen, NAT en routeringsinformatie.